ECCV 2020 論文大盤(pán)點(diǎn) - OCR 篇
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
本文盤(pán)點(diǎn)?ECCV 2020?與?OCR 相關(guān)論文,包括?Text Detection(文本檢測(cè))、Text Recognition(文本識(shí)別)、神經(jīng)架構(gòu)搜索+文本識(shí)別、文本超分辨率、Scene text spotting(將檢測(cè)和識(shí)別放一起,端到端文本識(shí)別)。

An End-to-End OCR Text Re-organization Sequence Learning for Rich-text Detail Image Comprehension
作者 |?Liangcheng Li, Feiyu Gao, Jiajun Bu, Yongpan Wang, Zhi Yu, Qi Zheng
單位 | 浙江大學(xué);阿里巴巴等
論文 |?https://www.ecva.net/papers/eccv_2020/
papers_ECCV/papers/123700086.pdf
備注 |?ECCV 2020

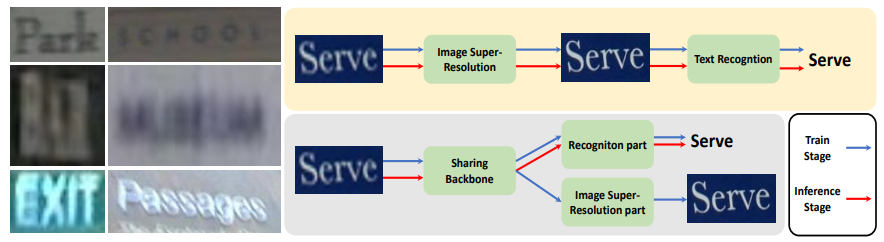
PlugNet: Degradation Aware Scene Text Recognition Supervised by a Pluggable Super-Resolution Unit
作者 |?Yongqiang Mou, Lei Tan, Hui Yang, Jingying Chen, Leyuan Liu, Rui Yan, Yaohong Huang
單位 | ImageDT圖匠數(shù)據(jù);華中師范大學(xué)
論文 |?https://www.ecva.net/papers/eccv_2020/
papers_ECCV/papers/123600154.pdf
備注 |?ECCV 2020
作者提出一個(gè)含有可插拔超分辨單元的端到端學(xué)習(xí)的文本識(shí)別方法(PlugNet),極大的解決了低質(zhì)量圖像識(shí)別的難題。
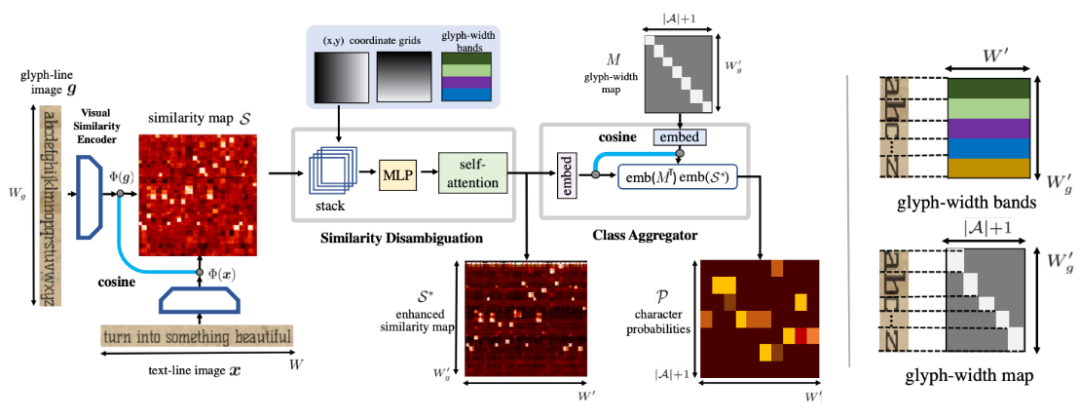
Adaptive Text Recognition through Visual Matching
作者 |?Chuhan Zhang,?Ankush Gupta,?Andrew Zisserman
單位 | 牛津大學(xué);DeepMind
論文 |?https://arxiv.org/abs/2009.06610
代碼 |?https://github.com/Chuhanxx/FontAdaptor
主頁(yè)?|?http://www.robots.ox.ac.uk/~vgg/research/FontAdaptor20/
備注 |?ECCV 2020
本文旨在解決文檔中文本識(shí)別的廣泛性與靈活性。引入一個(gè)新模型,利用語(yǔ)言中字符的重復(fù)性,將視覺(jué)表征學(xué)習(xí)和語(yǔ)言建模階段分離,將文本識(shí)別變成 shape matching 問(wèn)題。
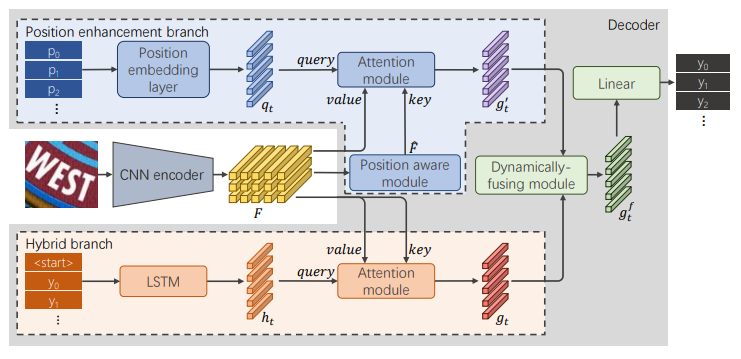
RobustScanner: Dynamically Enhancing Positional Clues for Robust Text Recognition
作者 |?Xiaoyu Yue,?Zhanghui Kuang,?Chenhao Lin,?Hongbin Sun,?Wayne Zhang
單位 | 商湯;西安交通大學(xué)
論文 |?https://arxiv.org/abs/2007.07542
備注 |?ECCV 2020
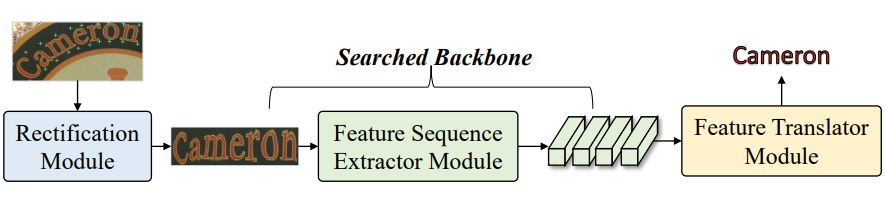
AutoSTR: Efficient Backbone Search for Scene Text Recognition
作者 |?Hui Zhang,?Quanming Yao,?Mingkun Yang,?Yongchao Xu,?Xiang Bai
單位 | 華中科技大學(xué);第四范式(北京)技術(shù)有限公司
論文 |?https://arxiv.org/abs/2003.06567
代碼 |?https://github.com/AutoML-4Paradigm/AutoSTR
備注 |?ECCV 2020
本項(xiàng)工作,作者受神經(jīng)架構(gòu)搜索(NAS)的成功啟發(fā),可以識(shí)別出比人類(lèi)設(shè)計(jì)更好的架構(gòu)。提出自動(dòng)STR(AutoSTR)來(lái)搜索依賴于數(shù)據(jù)的框架,以提高文本識(shí)別性能。
為STR設(shè)計(jì)了一個(gè)特定領(lǐng)域的搜索空間,其中包含了對(duì)操作的選擇和對(duì)下采樣路徑的約束。然后,提出一種兩步搜索算法,將操作和下采樣路徑解耦,在給定空間中進(jìn)行高效搜索。
實(shí)驗(yàn)證明,通過(guò)搜索數(shù)據(jù)相關(guān)的骨干,AutoSTR可以在標(biāo)準(zhǔn)基準(zhǔn)上以更少的FLOPS和模型參數(shù)超越最先進(jìn)的方法。
Scene Text Image Super-resolution in the wild
作者 |?Wenjia Wang,?Enze Xie,?Xuebo Liu,?Wenhai Wang,?Ding Liang,?Chunhua Shen,?Xiang Bai
單位 | 商湯;香港大學(xué);南京大學(xué);阿德萊德大學(xué);華中科技大學(xué)
論文 |?https://arxiv.org/abs/2005.03341
代碼 |?https://github.com/JasonBoy1/TextZoom
備注 |?ECCV 2020
介紹了第一個(gè)真正意義上的配對(duì)場(chǎng)景文本超分辨率數(shù)據(jù)集TextZoom,采用不同的焦距。用三個(gè)子集來(lái)標(biāo)注和分配數(shù)據(jù)集:分別是簡(jiǎn)單、中等和困難。
通過(guò)比較和分析在合成LR和提出的LR圖像上訓(xùn)練的模型,證明了所提出的數(shù)據(jù)集 TextZoom 的優(yōu)越性,并從不同方面證明了場(chǎng)景文本SR的必要性。
另外該問(wèn)還提出一個(gè)新的文本超分辨率網(wǎng)絡(luò),有三個(gè)新穎的模塊。通過(guò)在TextZoom上的訓(xùn)練和測(cè)試,以及公平的比較,證明它明顯超過(guò)了7種有代表性的SR方法。

Scene text spotting
Mask TextSpotter v3: Segmentation Proposal Network for Robust Scene Text Spotting
作者 |?Minghui Liao,?Guan Pang,?Jing Huang,?Tal Hassner,?Xiang Bai
單位 | 華中科技大學(xué);Facebook AI
論文 |?https://arxiv.org/abs/2007.09482
代碼 |?https://github.com/MhLiao/MaskTextSpotterV3
解讀|Mask TextSpotter v3 來(lái)了!最強(qiáng)端到端文本識(shí)別模型
備注 |?ECCV 2020
目前的方法多用 RPN 來(lái)進(jìn)行 integrating detection and recognition(集檢測(cè)與識(shí)別一體)的場(chǎng)景文本檢測(cè),但在極端長(zhǎng)寬比或不規(guī)則形狀的文本以及密集定向的文本中進(jìn)行操作有一定的困難。
因此,本文提出Mask TextSpotter v3,一個(gè)端到端可訓(xùn)練的場(chǎng)景文本發(fā)現(xiàn)器,采用 Segmentation Proposal Network (SPN) 來(lái)代替 RPN。SPN是無(wú)錨的,可以準(zhǔn)確地表示任意形狀的提案,所以優(yōu)于 RPN。Mask TextSpotter v3 可以處理極端長(zhǎng)寬比或不規(guī)則形狀的文本實(shí)例,并且識(shí)別精度不會(huì)受到附近文本或背景噪聲的影響。
具體來(lái)說(shuō),在Rotated ICDAR 2013數(shù)據(jù)集上的表現(xiàn)比最先進(jìn)的方法高出21.9%(旋轉(zhuǎn)魯棒性),在Total-Text數(shù)據(jù)集上的表現(xiàn)比最先進(jìn)的方法高出5.9%(形狀魯棒性),在MSRA-TD500數(shù)據(jù)集上的表現(xiàn)也達(dá)到了最先進(jìn)的水平(長(zhǎng)寬比魯棒性)。

AE TextSpotter: Learning Visual and Linguistic Representation for Ambiguous Text Spotting
作者 |?Wenhai Wang,?Xuebo Liu,?Xiaozhong Ji,?Enze Xie,?Ding Liang,?Zhibo Yang,?Tong Lu,?Chunhua Shen,?Ping Luo
單位 |?南京大學(xué);商湯;香港大學(xué);阿里巴巴;阿德萊德大學(xué)
論文 |?https://arxiv.org/abs/2008.00714
代碼 |?https://github.com/whai362/TDA-ReCTS
備注 |?ECCV 2020
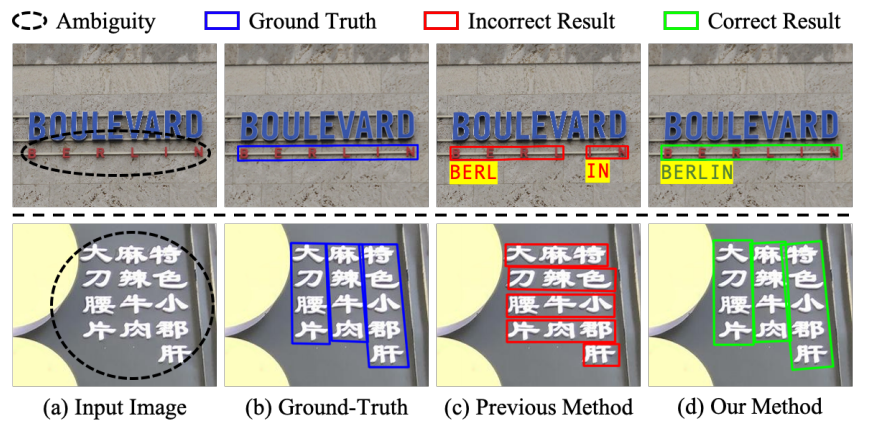
問(wèn)題:字符之間的間距較大或字符均勻分布在多行多列時(shí),會(huì)發(fā)生歧義,使得許多視覺(jué)上可信的字符分組。
方案:提出一種新型文本發(fā)現(xiàn)器,消除歧義文本發(fā)現(xiàn)器(AE TextSpotter),可以同時(shí)學(xué)習(xí)視覺(jué)和語(yǔ)言特征,以顯著降低文本檢測(cè)的歧義性。
優(yōu)點(diǎn):1、語(yǔ)言表征與視覺(jué)表征在同一框架,作者表示是第一次利用語(yǔ)言模型來(lái)改進(jìn)文本檢測(cè)。
2、利用精心設(shè)計(jì)的語(yǔ)言模塊降低了錯(cuò)誤文本行的檢測(cè)置信度,使其在檢測(cè)階段容易被修剪。
3、實(shí)驗(yàn)表明,AE TextSpotter比其他SOTA方法有很大的優(yōu)勢(shì)。例如,從IC19-ReCTS數(shù)據(jù)集中精心挑選了一組極度模糊的樣本進(jìn)行驗(yàn)證,所提出方法超過(guò)其他方法4%以上。