
【關(guān)于 Complex KBQA】 那些你不知道的事 (上)
作者:楊夕
項目地址:https://github.com/km1994/nlp_paper_study
面經(jīng)地址:https://github.com/km1994/NLP-Interview-Notes
論文:A Survey on Complex Knowledge Base Question Answering:Methods, Challenges and Solutions
會議:IJCAI'2021
論文地址:https://www.ijcai.org/proceedings/2021/0611.pdf
擴展長論文地址:https://arxiv.org%2Fpdf%2F2108.06688.pdf#=&zoom=130
個人介紹:大佬們好,我叫楊夕,該項目主要是本人在研讀頂會論文和復現(xiàn)經(jīng)典論文過程中,所見、所思、所想、所聞,可能存在一些理解錯誤,希望大佬們多多指正。
摘要
知識庫問答(KBQA)旨在回答知識庫(KB)上的問題。最近,大量研究集中在語義或句法復雜的問題上。本文詳細總結(jié)了復雜KBQA的典型挑戰(zhàn)和解決方案. 我們開始介紹有關(guān) KBQA 任務的背景。接下來,我們介紹了復雜 KBQA 的兩種主流方法,即基于語義解析(SP-based)的方法和基于信息檢索(IR-based)的方法。然后我們從兩大類的角度綜合回顧了先進的方法。具體地,我們闡述了它們對典型挑戰(zhàn)的解決方案。最后,我們總結(jié)并討論了未來研究的一些有希望的方向。
一、論文背景
知識庫 (KB) 是一種結(jié)構(gòu)化數(shù)據(jù)庫,其中包含形式(主題、關(guān)系、對象)的事實集合。已經(jīng)構(gòu)建了大型知識庫,例如 Freebase[Bollackeret al., 2008]、DBPedia [Lehmannet al., 2015] 和 Wikidata [Tanonet al., 2016],以服務于許多下游任務。基于可用的知識庫,知識庫問答 (KBQA) 是一項旨在以知識庫為知識源回答自然語言問題的任務。KBQA 的早期工作 [Bordeset al., 2015; Donget al., 2015; Huet al., 2018a; Lanet al., 2019a]專注于回答簡單的問題,其中只涉及一個事實。例如,“JK 羅琳出生在哪里?”是一個簡單的問題,可以僅使用“(J.K.羅琳,出生地,英國)”這一事實來回答。
二、論文動機
相比僅包含單個關(guān)系事實的簡單問題,復雜問題通常有以下幾個特征。我們以文中的例子 “誰是杰夫·普羅斯特秀提名的電視制片人的第一任妻子?” 為例:
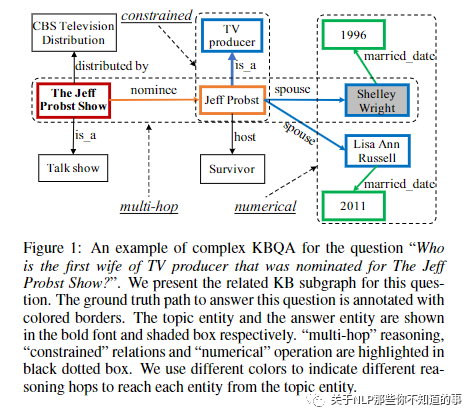
圖 1:問題“誰是杰夫·普羅斯特秀提名的電視制片人的第一任妻子?”問題的復雜 KBQA 示例。我們?yōu)檫@個問題提供了相關(guān)的知識庫子圖。回答這個問題的真實路徑用彩色邊框標注。主題實體和答案實體分別以粗體和陰影框顯示。“多跳”推理、“約束”關(guān)系和“數(shù)值”操作在黑色虛線框內(nèi)突出顯示。我們使用不同的顏色來表示從主題實體到達每個實體的不同推理跳數(shù)
需要在知識圖譜中做多跳推理 (multi-hop reasoning):該問題主干需要兩跳的推理,即“杰夫·普羅斯特秀提名的人”和“他的妻子”。
需要考慮題目中給的限制詞 (constrained relations):該問題中出現(xiàn)的限制詞“電視制片人”需要在回答問題的時候被考慮到。
需要考慮數(shù)字運算的情況 (numerical operations):該問題詢問涉及序數(shù)“第一任”,因此需要對召回的實體進行排序操作。
直接將傳統(tǒng)知識圖譜問答模型運用到復雜問題上,不管是基于語義解析的方法還是信息檢索的方法都將遇到新的挑戰(zhàn):
傳統(tǒng)方法無法支撐問題的復雜邏輯:
現(xiàn)有的 SP-based 的方法中使用的解析器難以涵蓋各種復雜的查詢(例如,多跳推理、約束關(guān)系和數(shù)值運算)。
以前的 IR-based 的方法可能無法回答復雜的查詢,因為它們排名是在沒有可追溯推理的情況下對小范圍實體進行的。
復雜問題包含了更多的實體,導致在知識圖譜中搜索空間變大:復雜問題中更多的關(guān)系和主題意味著更大的潛在邏輯形式的搜索空間,這將大大增加計算成本。同時,更多的關(guān)系和主題可能會阻止 IR-based 的方法檢索所有相關(guān)實體進行排名。3.兩種方法都將問題理解作為首要步驟:這兩種方法都將問題理解視為首要步驟。當問題在語義和句法方面變得復雜時,模型需要具有強大的自然語言理解和泛化能力。
通常 Complex KBQA 數(shù)據(jù)集缺少對正確路徑的標注:對于復雜的問題,將真實路徑標記為答案是很昂貴的。一般只提供問答對。這表明 SP-based 的方法和 IR-based 的方法必須分別在沒有正確邏輯形式和推理路徑注釋的情況下進行訓練。這種微弱的監(jiān)督信號給這兩種方法帶來了困難。
三、KBQA benchmark datasets
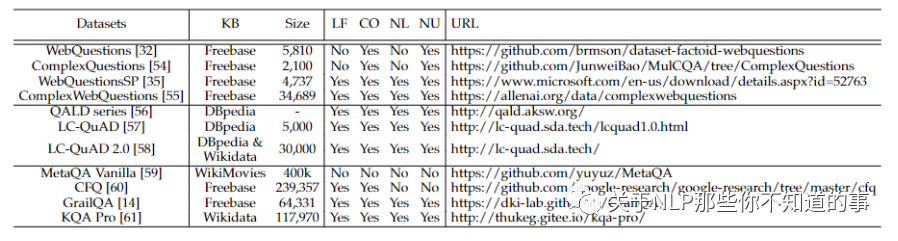
表 1:幾個復雜的 KBQA 基準數(shù)據(jù)集。“LF”表示數(shù)據(jù)集是否提供 Logic Forms,“NL”表示數(shù)據(jù)集是否包含 crowd workers 以重寫 Natural Language 中的問題
參考
A Survey on Complex Knowledge Base Question Answering:Methods, Challenges and Solutions
複雜知識庫問答:方法、挑戰(zhàn)與解決方案綜述
可能是目前最全面的知識庫復雜問答綜述解讀
[讀綜述] 關(guān)于知識圖譜問答的神經(jīng)網(wǎng)絡方法的介紹
KBQA知識庫問答論文分享