
【關(guān)于 Complex KBQA】 那些你不知道的事 (中)
作者:楊夕
項目地址:https://github.com/km1994/nlp_paper_study
面經(jīng)地址:https://github.com/km1994/NLP-Interview-Notes
論文:A Survey on Complex Knowledge Base Question Answering:Methods, Challenges and Solutions
會議:IJCAI'2021
論文地址:https://www.ijcai.org/proceedings/2021/0611.pdf
擴展長論文地址:https://arxiv.org%2Fpdf%2F2108.06688.pdf#=&zoom=130
個人介紹:大佬們好,我叫楊夕,該項目主要是本人在研讀頂會論文和復(fù)現(xiàn)經(jīng)典論文過程中,所見、所思、所想、所聞,可能存在一些理解錯誤,希望大佬們多多指正。
四、知識圖譜問答系統(tǒng)思路
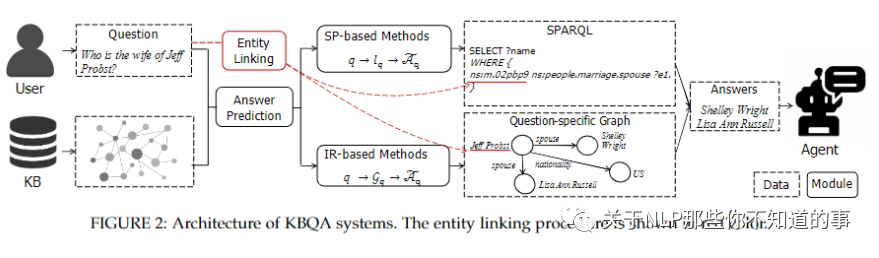
s1:實體連接 (entity linking),識別問題q的主題實體eq,其目的是將問題鏈接到知識庫中的相關(guān)實體。在這一步中,進行命名實體識別、消歧和鏈接。通常使用一些現(xiàn)成的實體鏈接工具來完成,例如 S-MART [24]、DBpediaSpotlight [25] 和 AIDA [26];
s2:利用答案預(yù)測模塊來預(yù)測答案 ?Aq。可以采用以下兩種方法進行預(yù)測:
基于語義解析 (SP-based) 方法:將問題解析為邏輯形式,并針對知識庫執(zhí)行它以找到答案;
基于信息檢索 (IR-based) 方法:檢索特定于問題的圖并應(yīng)用一些排名算法從頂部位置選擇實體。
s3:最后,將 KBQA 預(yù)測得到的預(yù)測答案 ?Aq 作為系統(tǒng)輸出返回給用戶;
五、預(yù)測答案兩類主流的方法
5.1 基于語義解析(SP-based)的方法
5.1.1 基于語義解析(SP-based)的方法整體結(jié)構(gòu)
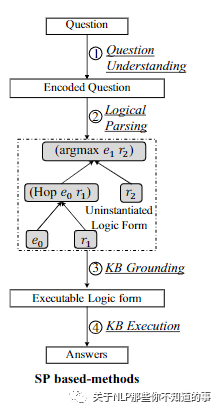
5.1.2 自然語言理解 (NLU) 模塊
介紹:從 自然語言的問題 中抽取出 意圖和實體。

可以使用 神經(jīng)網(wǎng)絡(luò)(如:LSTM、GRU、CNN、Transformer等方法對問題進行解析,識別 問題中 意圖和實體。
5.1.3 邏輯解析 (logical parsing) 模塊
介紹:將 NLU 結(jié)果轉(zhuǎn)化成解析式

5.1.4 知識圖譜實例化 (KB grounding) 模塊
介紹:生成的解析式 轉(zhuǎn)化為 可被 指定圖數(shù)據(jù)庫識別的查詢語句

通常情況下,Iq 包含了主題實體 eq。在有些工作中,(2)和(3)可以同步進行。
5.1.5 知識執(zhí)行 (KB execution) 模塊
介紹:利用 查詢語句 查詢 指定圖數(shù)據(jù)庫,返回問題答案
5.2 基于信息檢索(IR-based)的方法
5.2.1 基于信息檢索(IR-based)的方法整體結(jié)構(gòu)
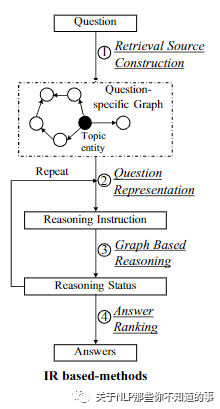
5.2.3 子圖構(gòu)建 (retrieval source construction) 模塊
介紹:從問題中的實體 eq 出發(fā),從知識圖譜中 抽取出和 查詢問題相關(guān)的子圖。
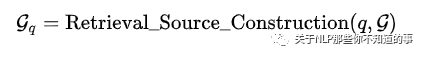
抽取的子圖大小會隨著抽取信息距離主題實體的距離增大呈指數(shù)增加。已有方法如 GraftNet 等通過 Personalized pagerank 保留重要實體控制子圖大小。
5.2.3 問題表達 (question representation) 模塊
介紹:對 自然語言的問題 q 進行 encoding,得到該問題 q 的 向量 ,再結(jié)合其他方法生成指令。

這里,{i^(k), k=1,...,n 是第 k 步推理得到的向量,該向量蘊含了問題在該步的指令。
5.2.4 基于圖結(jié)構(gòu)的推理 (graph based reasoning) 模塊
介紹:將在指令的指導(dǎo)下在抽取的子圖中做傳送和增強。推理過程將會產(chǎn)生推理狀態(tài)向量 {i^(k), k=1,...,n。該向量在具體方法中定義有所不同,如:預(yù)測實體的分布,關(guān)系的表達等。
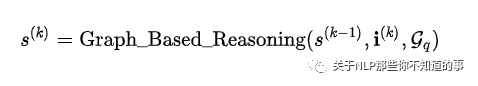
一些最新的工作重復(fù)(2)和(3)來實現(xiàn)顯性的多步推理。
5.2.5 答案排序 (answer ranking) 模塊
介紹:將第 n 步推理狀態(tài)向量用于最終的答案預(yù)測,排序高的實體被作為預(yù)測實體。

已有的工作通常會通過超參數(shù)閾值來選取預(yù)測答案實體。
基于信息檢索的方法訓(xùn)練目標是讓正確的答案實體排序高于其他實體。
5.3 基于語義解析(SP-based)的方法 vs 基于信息檢索(IR-based)的方法
基于語義解析(SP-based)的方法
優(yōu)點:可以通過生成表達邏輯形式來產(chǎn)生更可解釋的推理過程;
缺點:嚴重依賴于邏輯形式和解析算法的設(shè)計,這成為性能提升的瓶頸;
基于信息檢索(IR-based)的方法
優(yōu)點:對圖結(jié)構(gòu)進行復(fù)雜的推理并執(zhí)行語義匹配。這種范式自然適合流行的端到端 訓(xùn)練,并使基于語義解析(SP-based)的方法 更易于訓(xùn)練;
缺點:推理模型的黑盒風格使得中間推理的可解釋性較差。
參考
A Survey on Complex Knowledge Base Question Answering:Methods, Challenges and Solutions
複雜知識庫問答:方法、挑戰(zhàn)與解決方案綜述
可能是目前最全面的知識庫復(fù)雜問答綜述解讀
[讀綜述] 關(guān)于知識圖譜問答的神經(jīng)網(wǎng)絡(luò)方法的介紹
KBQA知識庫問答論文分享