
ResNets首次反超有監(jiān)督學(xué)習(xí)!DeepMind用自監(jiān)督實(shí)現(xiàn)逆襲,無需標(biāo)注

極市導(dǎo)讀
?近日,DeepMind又整了個(gè)新活:RELIC第二代!首次用自監(jiān)督學(xué)習(xí)實(shí)現(xiàn)了對(duì)有監(jiān)督學(xué)習(xí)的超越。莫非,今后真的不用標(biāo)注數(shù)據(jù)了?>>加入極市CV技術(shù)交流群,走在計(jì)算機(jī)視覺的最前沿

機(jī)器學(xué)習(xí)中,伴隨著更多高質(zhì)量的數(shù)據(jù)標(biāo)簽,有監(jiān)督學(xué)習(xí)模型的性能也會(huì)提高。然而,獲取大量帶標(biāo)注數(shù)據(jù)的代價(jià)十分高昂。
按照AI行業(yè)的膨脹速度,如果每個(gè)數(shù)據(jù)點(diǎn)都得標(biāo)記,「人工智能=有多少人工就有多智能」的刻薄笑話很可能會(huì)成為現(xiàn)實(shí)。

不過一直以來,表征學(xué)習(xí)、自監(jiān)督學(xué)習(xí)等辦法的「下游效能」至今未能超出有監(jiān)督學(xué)習(xí)的表現(xiàn)。
2022年1月,DeepMind與牛津大學(xué)、圖靈研究院針對(duì)此難題,聯(lián)合研發(fā)出了RELICv2,證明了在ImageNet中使用相同網(wǎng)絡(luò)架構(gòu)進(jìn)行同等條件下的對(duì)比,無標(biāo)注訓(xùn)練數(shù)據(jù)集的效果可以超過有監(jiān)督學(xué)習(xí)。
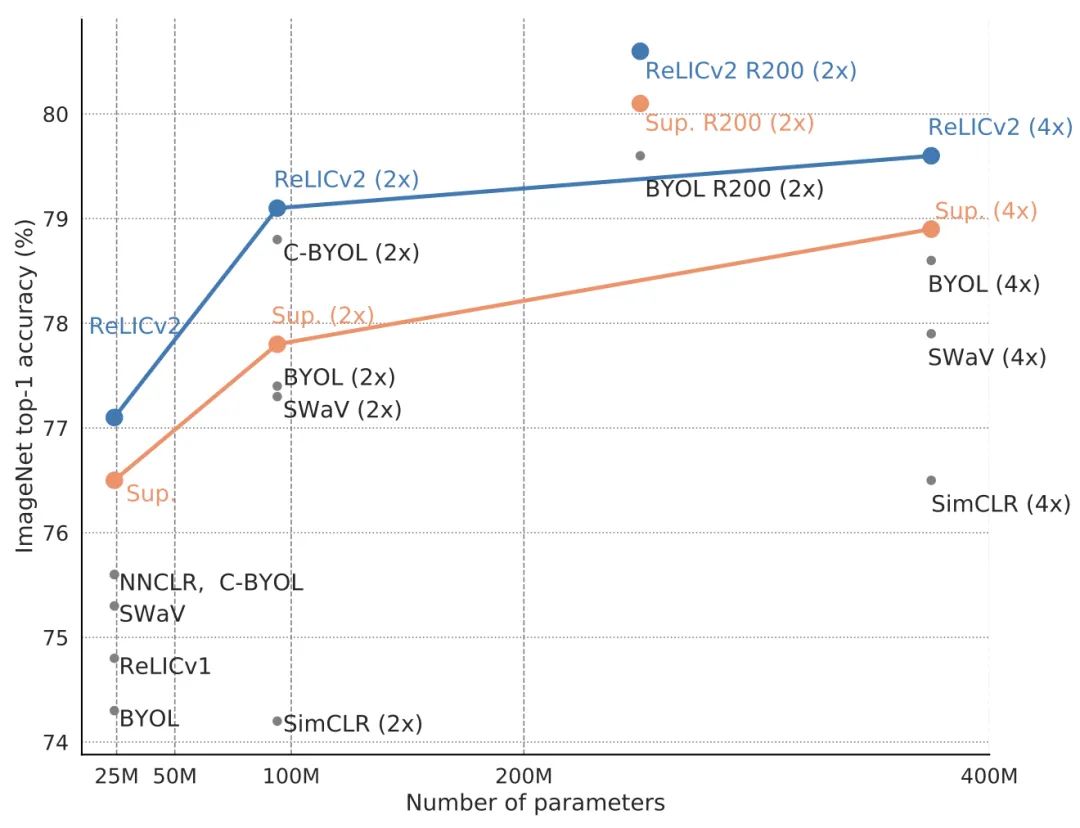
其中,RELICv2使用ResNet50時(shí)在ImageNet上實(shí)現(xiàn)了77.1%的top-1準(zhǔn)確率,而更大的ResNet模型則帶來了80.6%的top-1準(zhǔn)確率,以較大的優(yōu)勢(shì)超越了此前的自監(jiān)督方法。
為達(dá)到上述效果,研究者使用2021年問世的的「以因果預(yù)測(cè)機(jī)制進(jìn)行表征學(xué)習(xí)」(縮寫RELIC)的架構(gòu)搭建模型。
相較于RELIC,RELICv2多了一個(gè)可以選擇相似點(diǎn)和不同點(diǎn)的策略,相似點(diǎn)可以設(shè)計(jì)不變性的目標(biāo)函數(shù),不同點(diǎn)可以設(shè)計(jì)對(duì)比性質(zhì)的目標(biāo)函數(shù)。RELIC學(xué)習(xí)出的表征會(huì)更接近于底層數(shù)據(jù)的幾何性質(zhì)。這一特性使得這種方式學(xué)到的表征能更好地移用在下游任務(wù)上。
結(jié)果顯示,RELICv2不僅優(yōu)于其他競(jìng)爭(zhēng)方法,而且是第一個(gè)在橫跨1x,2x,和4x的ImageNet編碼器配置中持續(xù)優(yōu)于監(jiān)督學(xué)習(xí)的自監(jiān)督方法。
此外,在使用ResNet101、ResNet152、ResNet200等大型ResNet架構(gòu)的情況下,RELICv2也超過了有監(jiān)督基線模型的表現(xiàn)。
最后,盡管使用的是ResNet的架構(gòu),RELICv2也表現(xiàn)出了可以與SOTA的Transformer模型相提并論的性能。
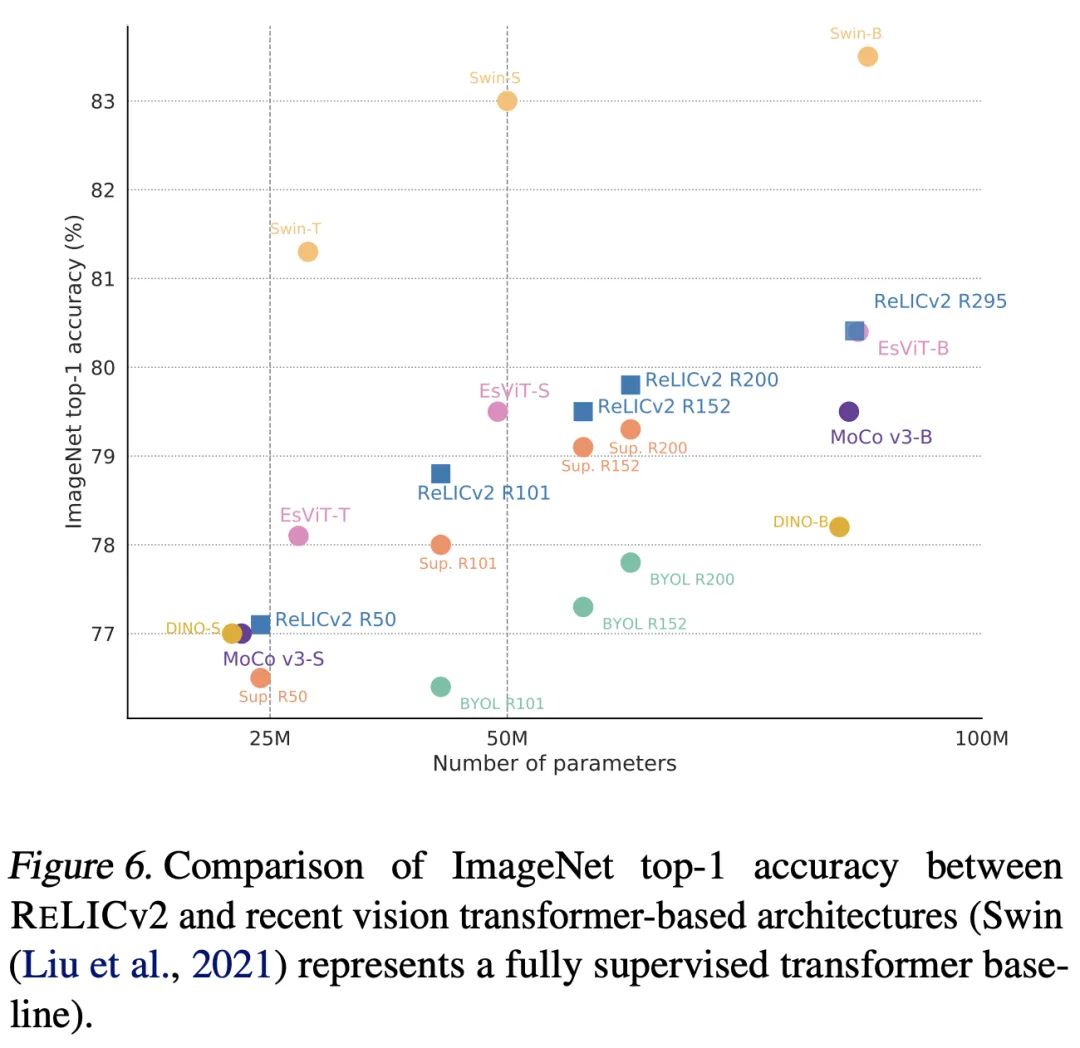
RELICv2和視覺Transformer模型之間的ImageNet top-1準(zhǔn)確率比較,Swin代表全監(jiān)督的Transformer基線
值得注意的是,雖然另有其它研究的結(jié)果也超過了這一基線,但它們使用了不同的神經(jīng)網(wǎng)絡(luò)架構(gòu),所以并非同等條件下的對(duì)比。
方法
此前,RELIC引入了一個(gè)不變性損失,定義為錨點(diǎn)xi和它的一個(gè)正樣本x+i之間的Kullback-Leibler分歧:
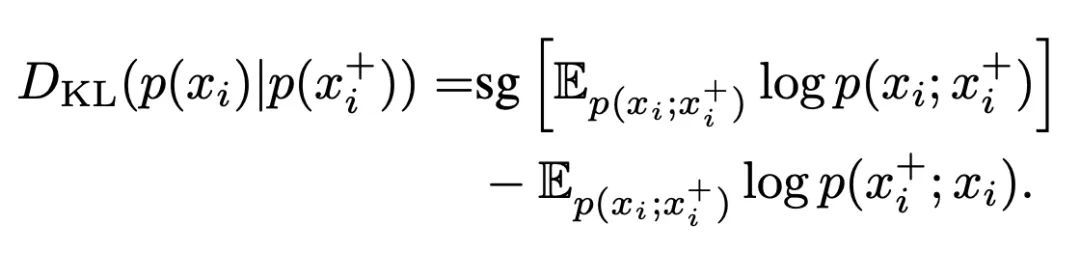
其中,梯度停止算子sg[-]不會(huì)影響KL-分歧的計(jì)算。
與RELIC類似,RELICv2的目標(biāo)是最小化對(duì)比負(fù)對(duì)數(shù)似然和不變損失的組合。
對(duì)于給定的mini-batch,損失函數(shù)為:
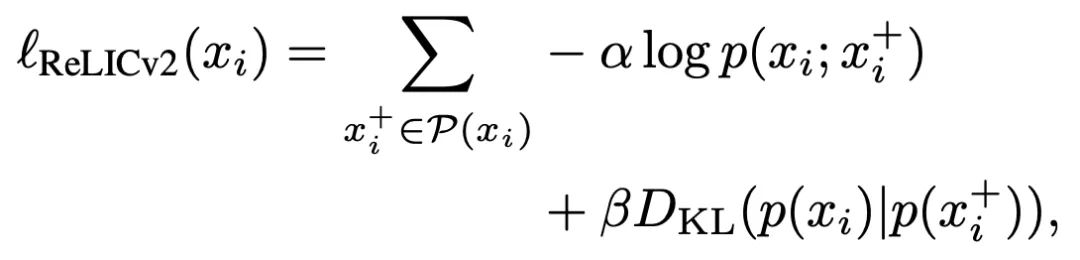
其中,α和β是標(biāo)量的超參,用于權(quán)衡對(duì)比和不變損失對(duì)整體目標(biāo)的相對(duì)重要性。
RELICv2與RELIC的不同之處在于如何選擇適當(dāng)?shù)恼?fù)樣本和目標(biāo)函數(shù)兩部分之間的組合關(guān)系。
增強(qiáng)方法方面,除了標(biāo)準(zhǔn)的SimCLR,作者還應(yīng)用了兩種策略:不同大小的隨機(jī)裁剪和顯著性背景移除。
負(fù)樣本的采樣方面,作者從所有的負(fù)樣本里隨機(jī)采樣,從而緩解假陰性的問題,也就是從同一個(gè)類別里采樣到負(fù)樣本對(duì)的問題。
for?x?in?batch:?#?load?a?batch?of?B?samples
??#?Apply?saliency?mask?and?remove?background
??x_m?=?remove_background(x)
??for?i?in?range(num_large_crops):
????#?Select?either?original?or?background-removed
????#?Image?with?probability?p_m
????x?=?Bernoulli(p_m)???x_m?:?x
????#?Do?large?random?crop?and?augment
????xl_i?=?aug(crop_l(x))
????
????ol_i?=?f_o(xl_i)
????tl_i?=?g_t(xl_i)
??for?i?in?range(num_small_crops):
????#?Do?small?random?crop?and?augment
????xs_i?=?aug(crop_s(x))
????#?Small?crops?only?go?through?the?online?network
????os_i?=?f_o(xs_i)
????
??loss?=?0
??#?Compute?loss?between?all?pairs?of?large?crops
??for?i?in?range(num_large_crops):
????for?j?in?range(num_large_crops):
??????loss?+=?loss_relicv2(ol_i,?tl_j,?n_e)
??#?Compute?loss?between?small?crops?and?large?crops
??for?i?in?range(num_small_crops):
????for?j?in?range(num_large_crops):
??????loss?+=?loss_relicv2(os_i,?tl_j,?n_e)
??scale?=?(num_large_crops?+?num_small_crops)?*?num_large_crops
??loss?/=?scale
??#?Compute?grads,?update?online?and?target?networks
??loss.backward()
??update(f_o)
??g_t?=?gamma?*?g_t?+?(1?-?gamma)?*?f_o
上????:RELICv2的偽代碼
其中,f_o是在線網(wǎng)絡(luò);g_t是目標(biāo)網(wǎng)絡(luò)絡(luò);gamma是目標(biāo)EMA系數(shù);n_e是負(fù)樣本的數(shù)量;p_m是掩碼應(yīng)用概率。
結(jié)果
ImageNet上的線性回歸
RELICv2的top-1和top-5準(zhǔn)確率都大大超過了之前所有SOTA的自監(jiān)督方法。
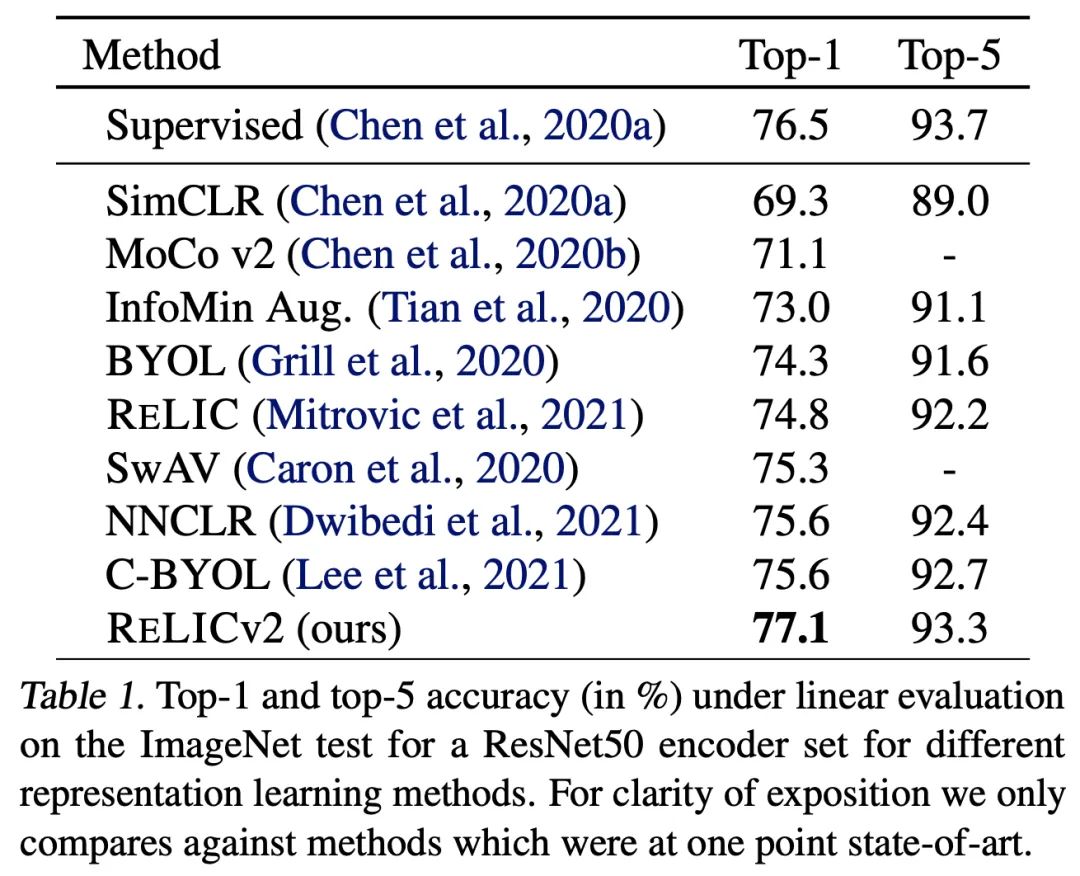
對(duì)于其他的ResNet架構(gòu),RELICv2在所有情況下都優(yōu)于監(jiān)督學(xué)習(xí),絕對(duì)值高達(dá)1.2%。

ImageNet上的半監(jiān)督訓(xùn)練
作者對(duì)表征進(jìn)行預(yù)訓(xùn)練,并利用ImageNet訓(xùn)練集中的一小部分可用標(biāo)簽,對(duì)所學(xué)的表征進(jìn)行重新修正。
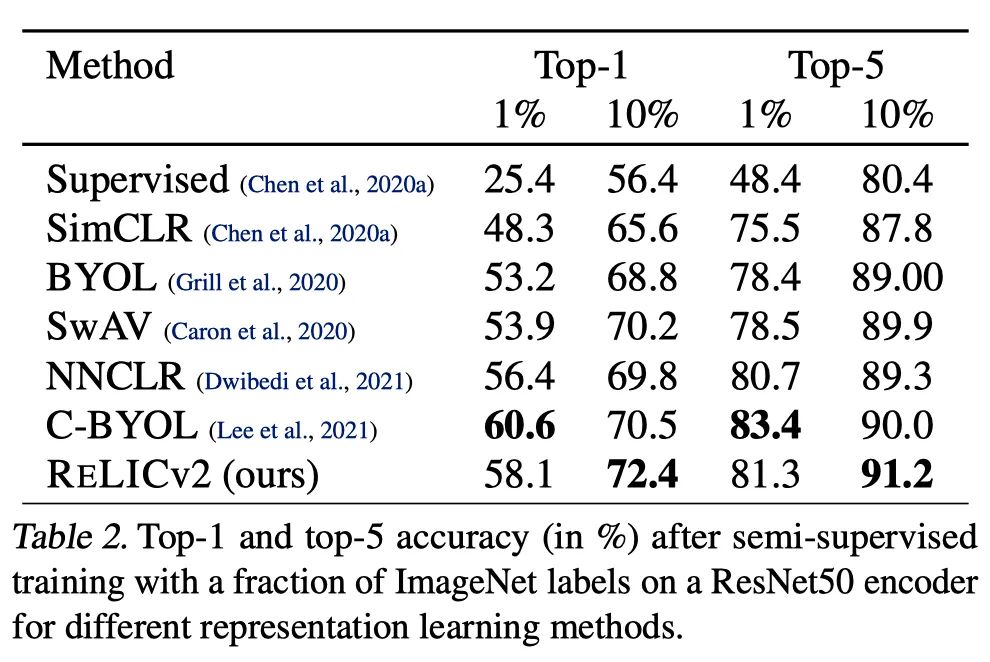
當(dāng)使用10%的數(shù)據(jù)進(jìn)行微調(diào)時(shí),RELICv2的表現(xiàn)好于監(jiān)督學(xué)習(xí)和此前所有SOTA的自監(jiān)督方法。
當(dāng)使用1%的數(shù)據(jù)時(shí),只有C-BYOL的表現(xiàn)好于RELICv2。
任務(wù)遷移
作者通過測(cè)試RELICv2表征的通用性,從而評(píng)估所學(xué)到的特征是否可以用在其他的圖像任務(wù)。
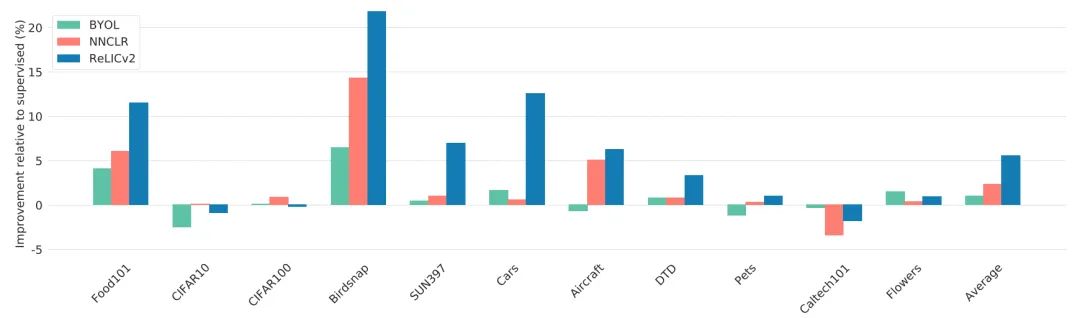
總的來說,RELICv2在11項(xiàng)任務(wù)中的7項(xiàng)都比監(jiān)督學(xué)習(xí)和競(jìng)爭(zhēng)方法都要好。
在所有任務(wù)中,RELICv2比監(jiān)督學(xué)習(xí)平均提高了5%以上,是NNCLR的兩倍。
其他視覺任務(wù)。為了進(jìn)一步評(píng)估所學(xué)表征的通用性,作者通過?netuning評(píng)估RELICv2在其他具有挑戰(zhàn)性的視覺任務(wù)中的表現(xiàn)。

可以看出,在PASCAL和Cityscapes上,RELICv2都比BYOL有明顯的優(yōu)勢(shì)。而對(duì)于專門為檢測(cè)而訓(xùn)練的DetCon,RELICv2也在PASCAL上更勝一籌。
在JFT-300M上的大規(guī)模遷移
作者使用JFT-300M數(shù)據(jù)集預(yù)訓(xùn)練表征來測(cè)試RELICv2在更大的數(shù)據(jù)集上的擴(kuò)展性,該數(shù)據(jù)集由來自超過18k類的3億張圖片組成。
其中,Divide and Contrast(DnC)是一種專門為處理大型和未經(jīng)整理的數(shù)據(jù)集而設(shè)計(jì)的方法,代表了當(dāng)前自監(jiān)督的JFT-300M預(yù)訓(xùn)練的技術(shù)水平。
當(dāng)在JFT上訓(xùn)練1000個(gè)epoch時(shí),RELICv2比DnC提高了2%以上,并且在需要較少的訓(xùn)練epoch時(shí),取得了比其他競(jìng)爭(zhēng)方法更好的整體性能。
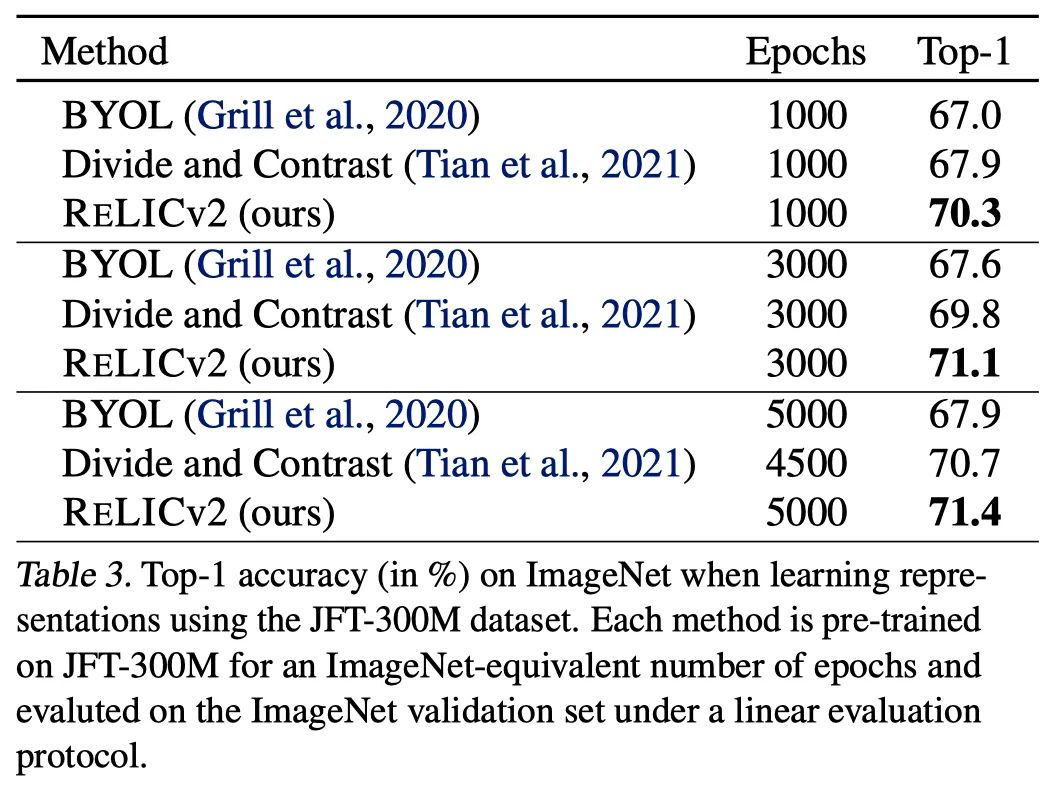
圖注:使用JFT-300M數(shù)據(jù)集學(xué)習(xí)表征時(shí)在ImageNet上的top-1準(zhǔn)確率
分析
通過計(jì)算所學(xué)表征之間的距離,可以了解到損失函數(shù)中的顯式不變量對(duì)RELICv2所學(xué)到的表征的影響。
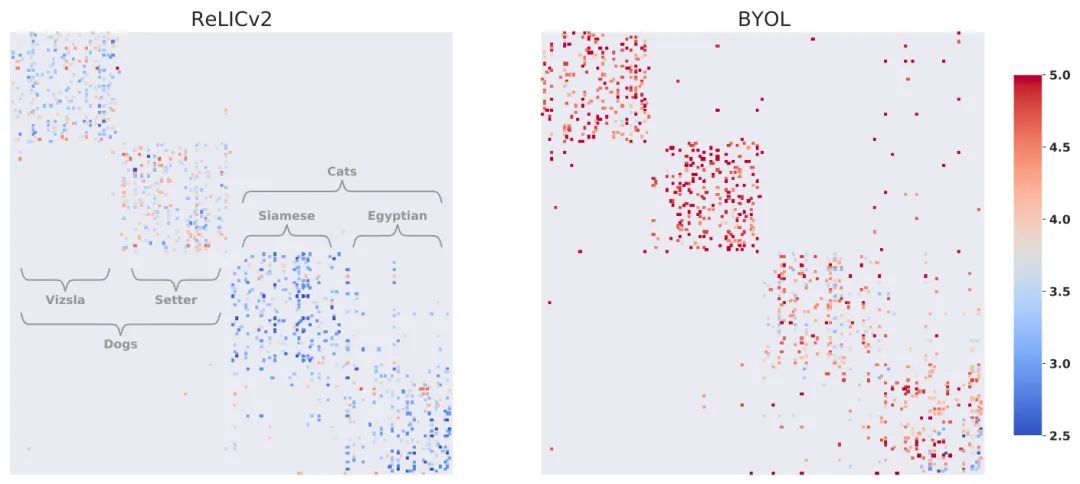
作者為此挑選了兩種狗(維茲拉犬與雪達(dá)犬)和兩種貓(暹羅貓和埃及貓)。在這四個(gè)類別中的每一個(gè)都有50個(gè)來自ImageNet驗(yàn)證集的點(diǎn)。
圖中,每一行代表一幅圖像,每一個(gè)彩色的點(diǎn)代表該圖像的五個(gè)最近的鄰居之一,顏色表示該圖像與最近的鄰居之間的距離。與基礎(chǔ)類結(jié)構(gòu)完全一致的表征會(huì)表現(xiàn)出完美的塊狀對(duì)角線結(jié)構(gòu);也就是說,它們的最近鄰居都屬于同一個(gè)基礎(chǔ)類。
可以看到,RELICv2學(xué)習(xí)到的表征之間更加接近,并且在類和超類之間表現(xiàn)出比BYOL更少的混淆。
為了量化所學(xué)潛在空間的整體結(jié)構(gòu),作者比較了所有的類內(nèi)和類間距離。
其中,l2-距離的比值越大,也就是說表征更好地集中在相應(yīng)的類內(nèi),因此也更容易在類與類之間進(jìn)行線性分離。
結(jié)果顯示,與監(jiān)督學(xué)習(xí)相比,RELICv2的分布向右偏移(即具有較高的比率),這表明使用線性分類器可以更好地分離表征。
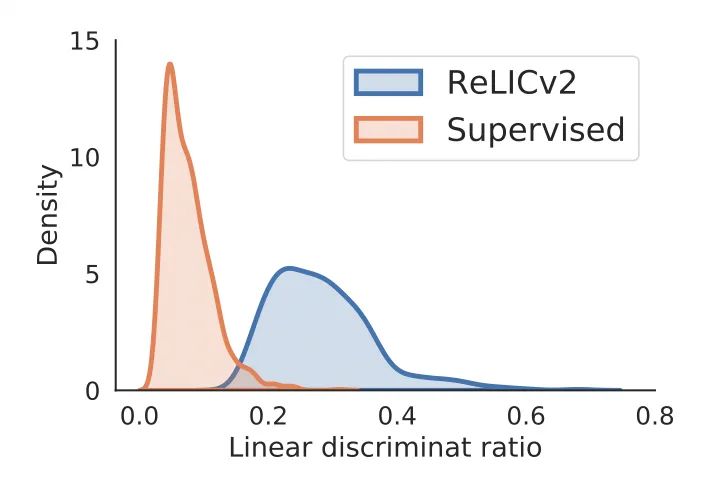
線性判別率的分布:在ImageNet驗(yàn)證集上計(jì)算的嵌入的類間距離和類內(nèi)距離的比率
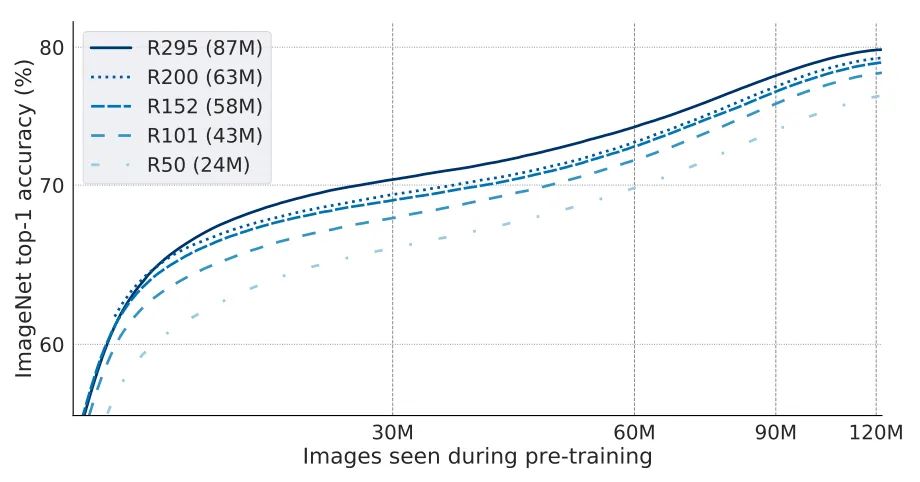
此外,作者也驗(yàn)證了其他工作的發(fā)現(xiàn)——模型越大就越具有樣本效率。也就是說,在相同精度下,大模型需要的樣本更少。
可以看到,為了達(dá)到70%的準(zhǔn)確性,ResNet50模型需要的迭代次數(shù)大約是ResNet295模型的兩倍。相比起來,ResNet295的參數(shù)數(shù)量大約是ResNet50的3.6倍(分別為87M和24M)。
結(jié)論
RELICv2首次證明了在沒有標(biāo)簽的情況下學(xué)習(xí)到的表征可以持續(xù)超越ImageNet上強(qiáng)大的有監(jiān)督學(xué)習(xí)基線。
在使用ResNet50編碼器進(jìn)行的同類比較中,RELICv2代表了對(duì)當(dāng)前技術(shù)水平的重大改進(jìn)。
值得注意的是,RELICv2優(yōu)于DINO和MoCo v3,并在參數(shù)數(shù)量相當(dāng)?shù)那闆r下表現(xiàn)出與EsViT類似的性能,盡管這些方法用了更強(qiáng)大的架構(gòu)和更多的訓(xùn)練。
參考資料:https://arxiv.org/abs/2201.05119
如果覺得有用,就請(qǐng)分享到朋友圈吧!
公眾號(hào)后臺(tái)回復(fù)“transformer”獲取最新Transformer綜述論文下載~

#?CV技術(shù)社群邀請(qǐng)函?#

備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測(cè)-深圳)
即可申請(qǐng)加入極市目標(biāo)檢測(cè)/圖像分割/工業(yè)檢測(cè)/人臉/醫(yī)學(xué)影像/3D/SLAM/自動(dòng)駕駛/超分辨率/姿態(tài)估計(jì)/ReID/GAN/圖像增強(qiáng)/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實(shí)項(xiàng)目需求對(duì)接、求職內(nèi)推、算法競(jìng)賽、干貨資訊匯總、與?10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動(dòng)交流~
