
輕量級姿態(tài)估計技巧綜述

極市導(dǎo)讀
?本文作者總結(jié)了目前自己實驗過的一些姿態(tài)估計的技巧,分為三個部分:數(shù)據(jù)處理/增強篇、結(jié)構(gòu)篇以及損失函數(shù)篇,更有相關(guān)復(fù)現(xiàn)代碼。本文將持續(xù)更新,歡迎關(guān)注~>>加入極市CV技術(shù)交流群,走在計算機視覺的最前沿
數(shù)據(jù)處理&增強篇
1. 正確的歸一化
將坐標值歸一化到(-0.5, 0.5)之間,公式為:
由于目標檢測的關(guān)系,姿態(tài)估計的對象大都會在圖像的中央,用這樣的歸一化能很大的加速模型收斂
2. Augmentation by Information Dropping(AID)
2020 COCO Keypoint Challenge 冠軍之路?
地址:https://zhuanlan.zhihu.com/p/210199401
這是COCO2020 冠軍團隊的論文。作者認為在姿態(tài)估計任務(wù)中,模型會使用兩種信息:外觀信息和約束信息。外觀信息是定位關(guān)鍵點的基礎(chǔ),而約束信息則在定位困難關(guān)鍵點時具有重要的指導(dǎo)意義。約束信息包括人體關(guān)鍵點之間固有的相互約束關(guān)系(如人體關(guān)節(jié)的活動度),以及人體和環(huán)境交互形成的約束關(guān)系。直觀上看,約束信息相比于外觀信息而言,更復(fù)雜多樣,對于網(wǎng)絡(luò)而言學(xué)習(xí)難度更大,這會使得在外觀信息充分的情況下,存在約束條件被忽視的可能性(模型會偷懶,不學(xué)習(xí)/使用約束信息)。基于此假設(shè),作者引入了信息丟失的正則化手段,通過在訓(xùn)練過程中以一定的概率丟失關(guān)鍵點的外觀信息,以此避免訓(xùn)練過程擬合外觀信息而忽視約束信息。

結(jié)構(gòu)篇
1. Mish
CoinCheung/pytorch-loss: label-smooth, amsoftmax, focal-loss, triplet-loss, lovasz-softmax. Maybe useful
地址:https://github.com/CoinCheung/pytorch-loss
一個更強的激活函數(shù),直接替換ReLU,使用后有漲點,但由于沒有inplace,顯存的占用幾乎要翻倍,需要自己權(quán)衡一下
Mish的作者更新了一個Hard版本用于移動設(shè)備,同時也加入了inplace
def hard_mish(x, inplace: bool = False) :
"""Implements the HardMish activation function
Args:
x: input tensor
Returns:
output tensor
"""
if inplace:
return x.mul_(0.5 * (x + 2).clamp(min=0, max=2))
else:
return 0.5 * x * (x + 2).clamp(min=0, max=2)
class HardMish(nn.Module):
"""Implements the Had Mish activation module from `"H-Mish" `_
This activation is computed as follows:
.. math::
f(x) = \\frac{x}{2} \\cdot \\min(2, \\max(0, x + 2))
"""
def __init__(self, inplace: bool = False) -> None:
super().__init__()
self.inplace = inplace
def forward(self, x):
return hard_mish(x, inplace=self.inplace)
近期出了一些輕量級模型的工程化優(yōu)化的工作,如pplcnet,esnet,rmnet等,大家普遍地使用了hardswish,因此我專門做了實驗對比一下hardmish和hardswish
訓(xùn)練了一個我自己魔改出來的輕量模型,結(jié)構(gòu)上是repvgg-like:
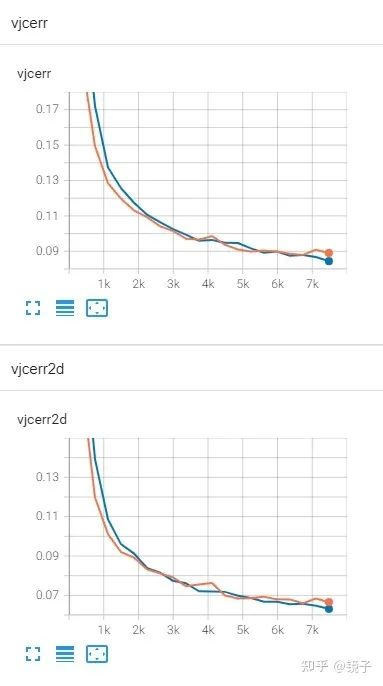
藍色是hardswish,黃色是hardmish,從我的實驗可以看出,在訓(xùn)練初期hardmish損失下降是更快的,但是后續(xù)的波動比較大,穩(wěn)定性不如hardswish。我的實驗在4卡上跑了兩天,到這里訓(xùn)練也還沒有結(jié)束,因此不好斷定最終收斂時的性能表現(xiàn),但總體上可以判斷的是,這二者的性能是接近的,但hardswish穩(wěn)定性更勝一籌。
顯存的占用上,都開inplace的情況下顯存使用基本一樣,而從計算量的角度對比如下:
hardmish
deploy macs: 127.173792
mnn_inference: 9.927172660827637
mnn_inference: 9.442970752716064
mnn_inference: 9.6360182762146
mnn_inference: 9.197959899902344
mnn_inference: 11.279244422912598
hardswish
deploy macs: 126.910368
mnn_inference: 11.386265754699707
mnn_inference: 11.019973754882812
mnn_inference: 8.461620807647705
mnn_inference: 9.613375663757324
mnn_inference: 11.782505512237549
relu
deploy macs: 126.646944
mnn_inference: 9.963874816894531
mnn_inference: 11.411187648773193
mnn_inference: 9.003558158874512
mnn_inference: 8.894507884979248
mnn_inference: 10.858681201934814
可以看出hardmish的計算量是高于hardswish的,因此綜合來看使用hardswish是更高性價比的選擇。
附上hardswish的pytorch實現(xiàn):
def hard_sigmoid(x, inplace=False):
return nn.ReLU6(inplace=inplace)(x + 3) / 6
def hard_swish(x, inplace=False):
return x * hard_sigmoid(x, inplace)
class HardSwish(nn.Module):
def __init__(self, inplace=False):
super(HardSwish, self).__init__()
self.inplace = inplace
def forward(self, x):
return hard_swish(x, inplace=self.inplace)
2. RepVGG
工業(yè)界非常solid的一個工作,利用重參化技巧,可以將多分支的卷積操作合并成一次卷積操作,且真正做到計算結(jié)果完全一致。在我實際的項目中,通過調(diào)整各階段模塊數(shù)和width得到的小模型,在推理速度一樣的情況下精度能甩shufflenet和mobilenet很多。
更多細節(jié)可以去看作者的文章:
丁霄漢:RepVGG:極簡架構(gòu),SOTA性能,讓VGG式模型再次偉大(CVPR-2021)
https://zhuanlan.zhihu.com/p/344324470
3. OKDHP和NetAug
OKDHP的全稱是Online Knowledge Distillation for Efficient Pose Estimation,總體的思路是為要訓(xùn)練的輕量模型增加幾個分支,每個分支都學(xué)跟原來模型一樣的東西,每個分支可以跟原來的模型一樣,也可以不一樣,這樣相當(dāng)于同時訓(xùn)練了多個小模型,將結(jié)果進行集成。由于集成學(xué)習(xí)的思想,我們知道小模型集成后的結(jié)果往往是好于單個模型的,因此我們可以把集成的結(jié)果當(dāng)成蒸餾中教師網(wǎng)絡(luò)的輸出,讓小模型去逼近集成的結(jié)果。

傳統(tǒng)的蒸餾學(xué)習(xí)需要先訓(xùn)練一個大網(wǎng)絡(luò),訓(xùn)練完畢后作為教師,然后讓小網(wǎng)絡(luò)逼近教師的輸出,蒸餾的對象可以是feature也可以是logits。而這里通過集成得到了一個更強的網(wǎng)絡(luò),我們可以比作是集成得到了一個學(xué)習(xí)能力更強的學(xué)霸學(xué)生,讓普通學(xué)生跟這個學(xué)霸學(xué)習(xí),盡管大家都是一樣的起點,但學(xué)霸能力更強,所以普通學(xué)生還是可以從他身上學(xué)到一點東西。也可以看成是幾個普通學(xué)生每次學(xué)完后開會互相討論一下,總結(jié)經(jīng)驗教訓(xùn),然后大家都去學(xué)習(xí)這個總結(jié)后的結(jié)果。
這篇文章第一次看后的感覺說實話不是很驚艷,就是雖然相信它能漲點,但又感覺提升會很有限,而且為此要付出成倍的顯存感覺很雞肋,所以一直懶得動手做實驗。直到最近看了NetAug這篇工作后突然感覺理論上通透了,OKDHP很像是NetAug的一個特殊子集,增加分支其實就是在對網(wǎng)絡(luò)進行增強,小模型由于能力弱欠擬合,所以需要網(wǎng)絡(luò)增強技術(shù)來輔助學(xué)習(xí)。
NetAug也是一篇很不錯的工作,不過我覺得最重要的還是論證了網(wǎng)絡(luò)增強和正則化在大模型和小模型上的意義,看完后雖然感覺很有道理但并不想實際去跑實驗(因為感覺太花里胡哨了),所以提起勁兒把一直擱置的OKDHP跑了一下,這里貼一下我的實驗結(jié)果吧。
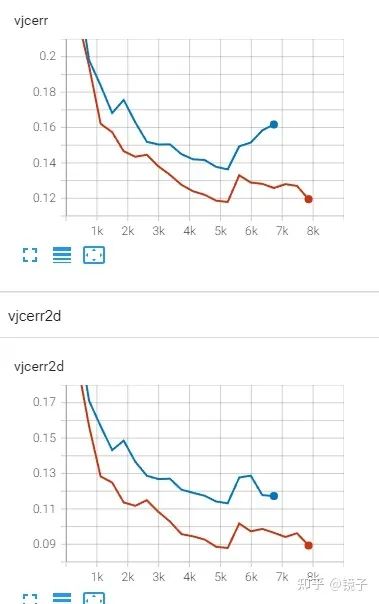
藍色是一個輕量級模型,紅色是把原模型復(fù)制了兩份后得到了一個三分支的集成模型,三個分支分別計算坐標損失,以及求每個分支與集成得到的feature的損失,這里的損失我用的KL散度,求之前記得過softmax不然會出現(xiàn)Nan。我沒有用作者提出的FAU,因為論文里的實驗對比FAU聚合的特征只比Mean完的結(jié)果高0.3%,所以簡單起見我直接對三個分支的feature相加求平均了。

驗證集上的結(jié)果是單個初始模型所在分支的結(jié)果,而非集成后的指標,所以能看到網(wǎng)絡(luò)增強+蒸餾確實是可以讓小模型學(xué)得更好的。
作者的文章解讀:
蘭青:ICCV 2021 | 利用在線知識蒸餾進行高效2D人體姿態(tài)估計
https://zhuanlan.zhihu.com/p/399742423
在NetAug文中有論證蒸餾跟網(wǎng)絡(luò)增強是正交關(guān)系,二者的收益是可以疊加的,OKDHP主要收益來源應(yīng)該還是在于蒸餾,要更好地利用網(wǎng)絡(luò)增強的收益,還應(yīng)該在計算損失時,分別用幾個頭部來聚合不同分支的結(jié)果(以三分支為例的話,可以分組成1+2,1+3,2+3,1+2+3等形式,把不同分支的特征concat傳入頭部計算損失),感覺上這樣應(yīng)該還能再提升一波,等以后有空我會再驗證一下。
損失函數(shù)篇
1. DSNT
anibali/dsntnn: PyTorch implementation of DSNT (github.com)
地址:https://github.com/anibali/dsntnn
比起主流的預(yù)測heatmap再使用argmax獲得最大響應(yīng)點的方法,作者提出用soft-argmax方法,直接從featuremap計算得到近似的最大響應(yīng)點,從而模型可以直接對坐標值進行回歸預(yù)測。
該方法的好處是:
可以極大節(jié)約顯存,減少了很多代碼量(省去了高斯熱圖的生成) 計算速度很快(省去argmax) 訓(xùn)練過程全部可微分 能取得還不錯的效果
但是從近年的新論文實驗對比,基于坐標回歸的方法,先天缺少空間和上下文信息,這限制了方法的性能上限
補充:
DSNT這種regression-based method對移動端非常友好,在移動設(shè)備上為了提高fps往往特征圖會壓到14x14甚至7x7,這個尺度下heatmap根本用不了 另一個好處是可以比較方便地混合使用2d和3d訓(xùn)練數(shù)據(jù),由于每一軸上的坐標都是通過將特征圖求和壓縮到一維再求期望得到的,因此可以很容易地用2d數(shù)據(jù)監(jiān)督3d特征圖(2d只比3d少算一次回歸)
2. Bone Loss
這個技巧我是從Weakly-Supervised Mesh-Convolutional Hand Reconstruction in the Wild(CVPR2020 Oral)這篇文章里看到的,第一眼就感覺intuitively make sense,實驗過后發(fā)現(xiàn)確實可以大大加速網(wǎng)絡(luò)的收斂。
計算公式如下:
其中J_2D是模型預(yù)測的關(guān)鍵點,Y_2D是GroundTruth,該公式約束了每個關(guān)鍵點之間的空間關(guān)系,同時相當(dāng)于約束了每根骨頭的長度,直覺上就能感覺到能幫助學(xué)習(xí)到骨頭長度關(guān)系,避免預(yù)測出一些詭異的不存在的姿態(tài)。
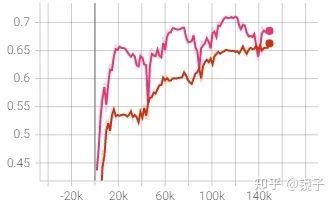
這是在我的數(shù)據(jù)集上的實驗結(jié)果,從上向下分別是baseline,使用了AID,增加了bone loss后,L2 loss的變化
PS:該實驗使用的是DSNT,使用了余弦退火學(xué)習(xí)率衰減

一開始我以為Bone Loss只能在2D坐標點上使用,這其實大大限制了它的使用場景,畢竟目前主流的方法還是基于Heatmap的。后來我做了實驗對比后發(fā)現(xiàn),在Heatmap方法上仍然是適用的,由下圖對比可以看到,相同的模型和訓(xùn)練參數(shù),僅僅增加了Bone Loss后的收斂速度,真的爽
下圖用的metric是joint accuracy:
把我實現(xiàn)的版本傳到了github,非常簡單但是實用,分享給有需要的小伙伴,如果樂意的話可以給我一個star~
https://github.com/674106399/JointBoneLoss
有部分小伙伴對這個loss有一點疑問,heatmap的矩陣相減是沒有物理意義的,所以我實現(xiàn)的版本里求的是兩個矩陣的Frobenius范數(shù),來比較矩陣相似度,同時兼容了heatmap和坐標值。
另外有小伙伴反映,在小數(shù)據(jù)上使用boneloss有掉點的情況,對應(yīng)的調(diào)整是可以把原本的求每個點與所有點的距離,改成只求相連節(jié)點之間的距離,只需要把原代碼中兩層for循環(huán)改成直接給兩個數(shù)組賦值即可。
3. Automatic Weighted Loss
地址:https://github.com/Mikoto10032/AutomaticWeightedLoss
由于模型有多個頭部,進行關(guān)鍵點預(yù)測、手存在性預(yù)測、手勢識別等任務(wù)(包括使用Bone Loss),因此可以使用Multi-task learning的方法來動態(tài)調(diào)節(jié)每個任務(wù)的權(quán)重,將不同的loss拉到統(tǒng)一尺度下,這樣就容易統(tǒng)一,具體的辦法就是利用同方差的不確定性,將不確定性作為噪聲進行訓(xùn)練。
注意:這個方法并不總是能帶來提升,在一些任務(wù)上反而會掉點,建議先在小數(shù)據(jù)上驗證后再使用。
4. L1 Loss
在對坐標進行回歸的時候,早些時候的文章大都直接用L2 loss,但隨著近些年的發(fā)展,大量的實驗表明了L1 loss在大部分情況下都會優(yōu)于L2 loss。
從極大似然估計的角度來看,損失函數(shù)的選擇實際上是基于對目標分布的假設(shè),如果假設(shè)目標為高斯分布,那么就應(yīng)該用L2 loss,如果假設(shè)為拉普拉斯分布,則應(yīng)該使用L1 loss。具體的公式推導(dǎo)可以看Human Pose Regression with Residual Log-likelihood Estimation這篇paper。
5. RLE
這篇ICCV Oral的解讀可以見我的專欄(但是沒有上面L1跟拉普拉斯分布對應(yīng)的公式推導(dǎo),得去看原文)
鏡子:論文筆記及思考:Human Pose Regression with Residual Log-likelihood Estimation(ICCV 2021 Oral)
https://zhuanlan.zhihu.com/p/395521994
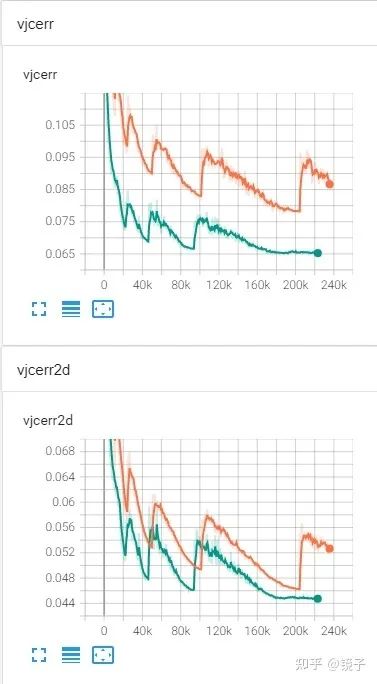
只能說非常厲害,強烈推薦使用,至于有多好用呢,我貼一個還沒訓(xùn)練完的RLE跟Integral Pose的對比(RLE結(jié)尾階段epoch的學(xué)習(xí)率我做了抹平,前面跟原實驗保持一致,曲線還是足夠說明問題了):
后處理篇
1. DARK
地址:https://github.com/ilovepose/DarkPose
這是COCO2020 亞軍團隊的論文。基于heatmap的方法往往存在一個分辨率變化的編碼-解碼過程,即原始圖片分辨率較大,需要先縮小后才能輸入模型進行預(yù)測,得到預(yù)測結(jié)果后還原到原始分辨率,再得到預(yù)測坐標。這個過程就會引入很多誤差:
編碼過程:GT在縮小后,渲染得到的高斯熱圖是有誤差的 解碼過程:預(yù)測的heatmap在還原到原始分辨率后,得到的坐標是有誤差的
對于第二種誤差,已經(jīng)有人總結(jié)過一個標準過程,即將預(yù)測的坐標,由最大響應(yīng)點向第二大響應(yīng)點的方向,移動0.25個像素。只是這樣的一個手工設(shè)計的偏移補救措施,就能帶來極大的性能提升。
本文假設(shè)預(yù)測的heatmap是滿足二維高斯分布的,因此基于heatmap的一階導(dǎo)數(shù)和二階導(dǎo)數(shù)來計算偏移方向,顯然這比由最大響應(yīng)點向第二大響應(yīng)點的方向更有說服力。
但在驗證中發(fā)現(xiàn),預(yù)測的heatmap并不嚴格遵守高斯分布,會出現(xiàn)多峰情況,因此增加了一個步驟,對預(yù)測的heatmap進行平滑處理,使結(jié)果符合假設(shè)。這一步是為上面提出的解碼方法服務(wù)的,用于保證解碼效果的準確性。
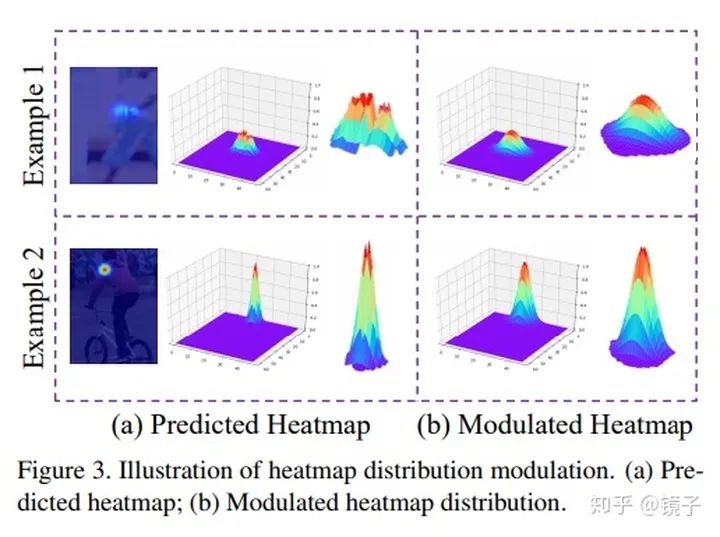

一圖勝千言,該方法對DSNT幾乎是吊打。在目前SOTA方法上也可以即插即用地產(chǎn)生巨大提升。
2. 指數(shù)滑動平均濾波
在實際的部署應(yīng)用中,輕量級模型的輸出不可避免地會出現(xiàn)抖動,一個比較簡單的處理方式是添加滑動濾波,用輕微的延遲來換取輸出的穩(wěn)定,具體原理和代碼可以看我這篇文章:
鏡子:用指數(shù)滑動平均濾波來穩(wěn)定輕量模型的輸出
https://zhuanlan.zhihu.com/p/433571477
如果覺得有用,就請分享到朋友圈吧!
公眾號后臺回復(fù)“CVPR21檢測”獲取CVPR2021目標檢測論文下載~

#?CV技術(shù)社群邀請函?#

備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標檢測-深圳)
即可申請加入極市目標檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學(xué)影像/3D/SLAM/自動駕駛/超分辨率/姿態(tài)估計/ReID/GAN/圖像增強/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實項目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、與?10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動交流~
