
Python爬蟲 | 批量爬取今日頭條街拍美圖
點(diǎn)擊上方“Python爬蟲與數(shù)據(jù)挖掘”,進(jìn)行關(guān)注 回復(fù)“書籍”即可獲贈Python從入門到進(jìn)階共10本電子書
浮云一別后,流水十年間。
感分割線")

01
前言

02
網(wǎng)頁分析
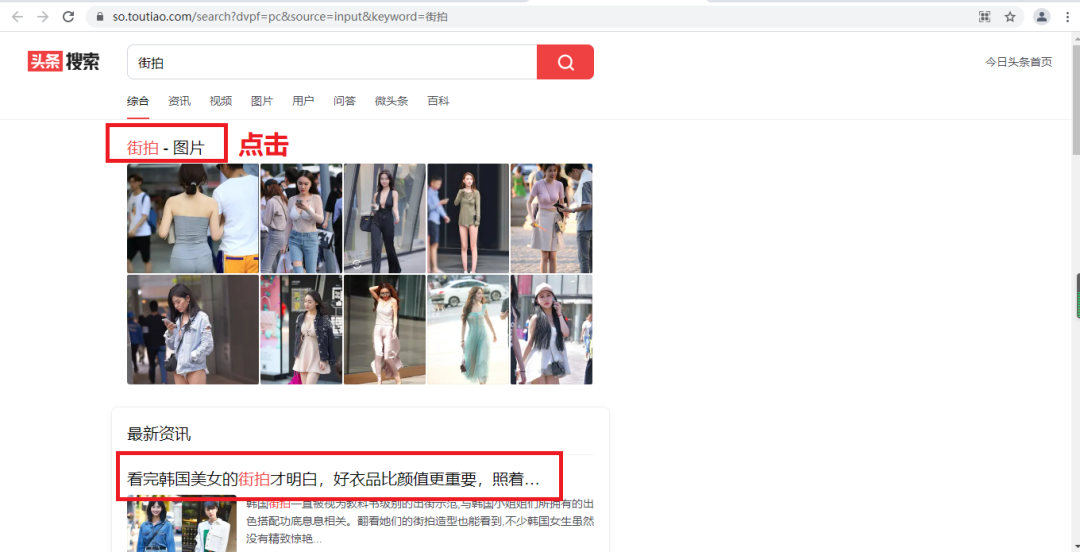

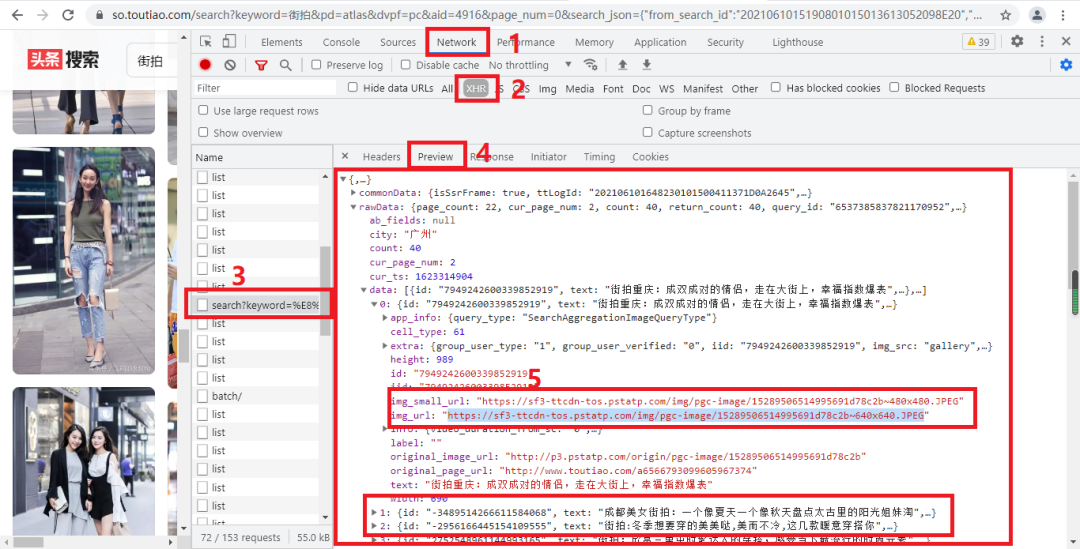
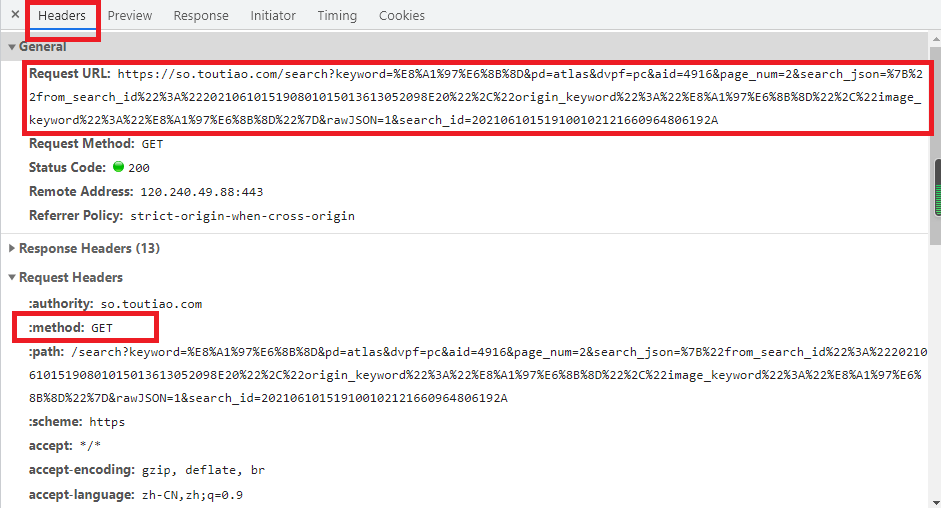
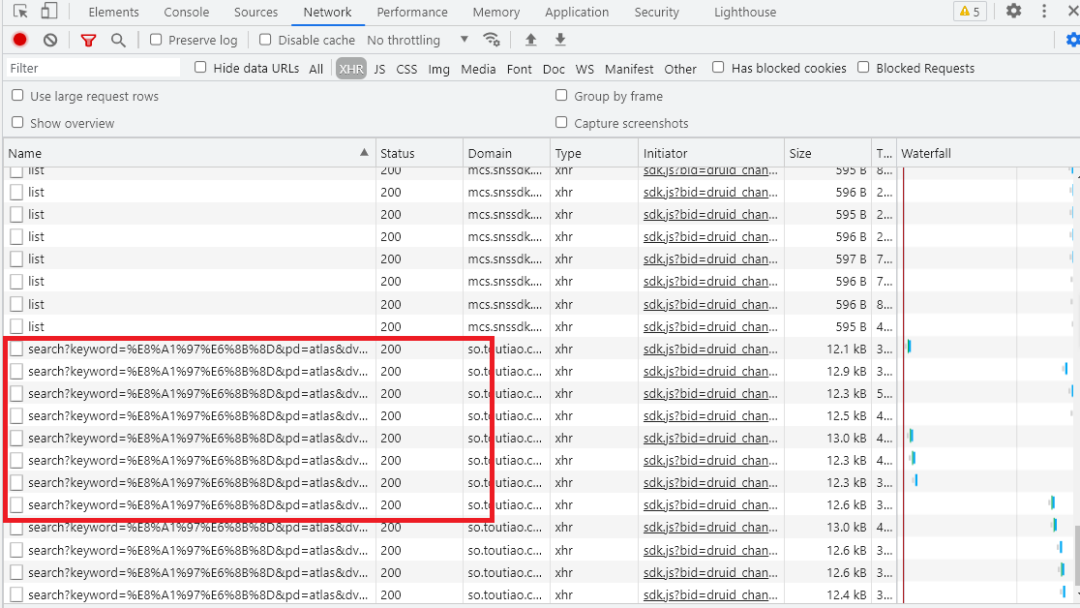
03
爬蟲實(shí)戰(zhàn)
def get_page(page_num):
global headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36',
}
params = {
'keyword':urllib.parse.unquote('%E8%A1%97%E6%8B%8D'),
'pd':'atlas',
'dvpf':'pc',
'aid':4916,
'page_num':page_num,
'search_json':'%7B%22from_search_id%22%3A%22202106100003510102121720341003A4ED%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id':'202106100004290101500200495C05B763'
}
url='https://so.toutiao.com/search?'+urlencode(params)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code==200:
return response.json()
except requests.ConnectionError:
return None
def get_images(json):
images=json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
def saving_img(link):
global name
print(f'-------正在打印第{name}張圖片')
data=requests.get(link,headers=headers).content
with open(f'image1/{name}.jpg','wb')as f:
f.write(data)
name+=1
def main(paga_num):
json=get_page(paga_num)
for link in get_images(json):
saving_img(link)
if __name__ == '__main__':
for i in range(0,2):
main(i)
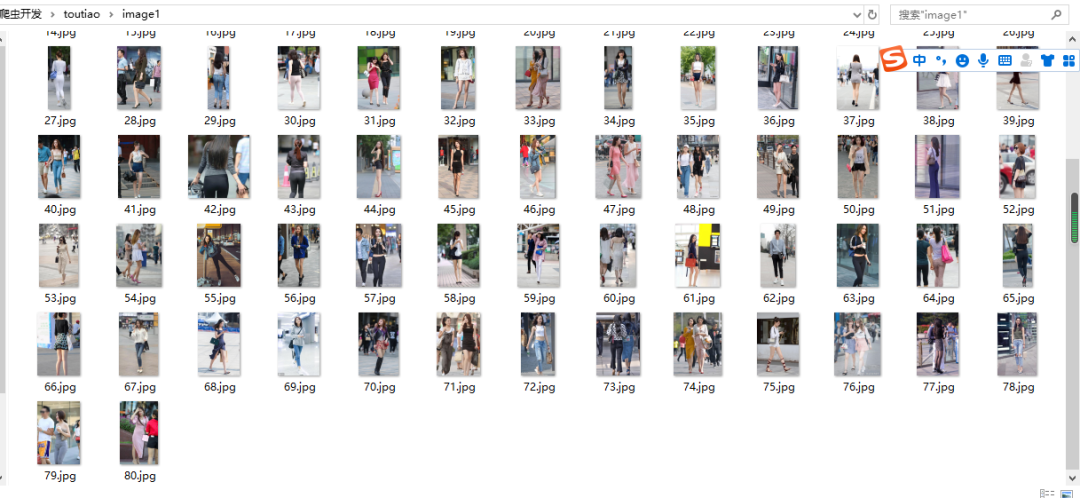
04
小結(jié)
------------------- End -------------------
往期精彩文章推薦:
一篇文章教會你用Python抓取抖音app熱點(diǎn)數(shù)據(jù)
手把手教你進(jìn)行pip換源,讓你的Python庫下載嗖嗖的
手把手教你用免費(fèi)代理ip爬數(shù)據(jù)

歡迎大家點(diǎn)贊,留言,轉(zhuǎn)發(fā),轉(zhuǎn)載,感謝大家的相伴與支持
想加入Python學(xué)習(xí)群請在后臺回復(fù)【入群】
萬水千山總是情,點(diǎn)個【在看】行不行
/今日留言主題/
隨便說一兩句吧!
評論
圖片
表情