本文約3500字,建議閱讀14分鐘
本文文章簡要介紹了研究人員在圖像識別算法和圖像數(shù)據(jù)方面的演變,并總結(jié)了現(xiàn)在的一些熱門話題。
三十多年來,許多研究人員在圖像識別算法和圖像數(shù)據(jù)方面積累了豐富的知識。如果你對圖像訓(xùn)練感興趣但不知道從哪里開始,這篇文章會是一個(gè)很好的開始。這篇文章簡要介紹了過去的演變,并總結(jié)了現(xiàn)在的一些熱門話題。ImageNet 的起源
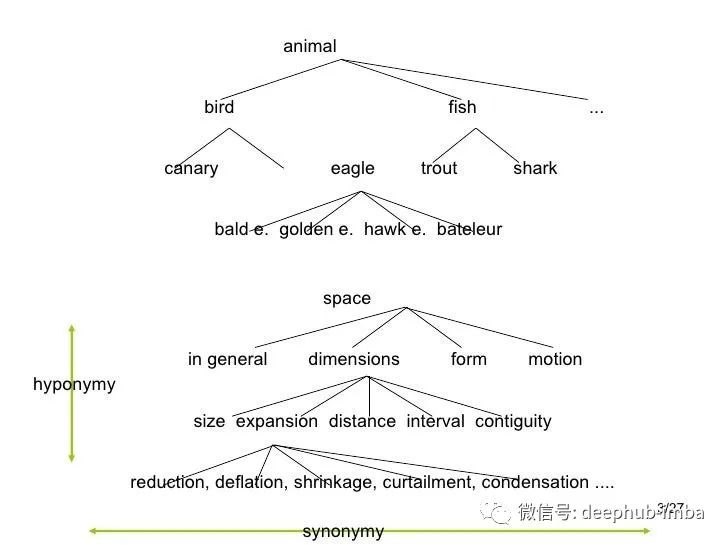
在 2000 年代初期,大多數(shù) AI 研究人員都專注于圖像分類問題的模型算法,但缺乏數(shù)據(jù)樣本,研究人員需要大量圖像和相應(yīng)的標(biāo)簽來訓(xùn)練模型。這激發(fā)了 ImageNet 的創(chuàng)建。ImageNet 由斯坦福大學(xué)的人工智能研究員李飛飛老師構(gòu)思和帶頭組建。2007 年,當(dāng)她開始構(gòu)思 ImageNet 的想法時(shí),她會見了普林斯頓大學(xué)教授 Christiane Fellbaum(WordNet 的創(chuàng)建者之一),并討論了該項(xiàng)目。WordNet 是用于名詞、動(dòng)詞、形容詞和副詞之間語義關(guān)系的詞匯自然語言處理 (NLP) 數(shù)據(jù)庫。它有 155,327 個(gè)詞,組織在 175,979 個(gè)同義詞組中,稱為同義詞組(有些詞只有一個(gè)同義詞組,有些詞有幾個(gè)同義詞組)。如果在 WordNet 中將圖像附加到單詞上不是很好嗎?這就是 ImageNet 的起源。ImageNet 將成百上千的圖像與 WordNet 中的同義詞集相關(guān)聯(lián)。從那時(shí)起,ImageNet 在計(jì)算機(jī)視覺和深度學(xué)習(xí)的進(jìn)步中發(fā)揮了重要作用。這些數(shù)據(jù)可供研究人員免費(fèi)用于非商業(yè)用途。ImageNet 數(shù)據(jù)庫有超過 1400 萬張圖像 (14,197,122),分為 21,841 個(gè)子類別。數(shù)據(jù)集中的每張圖像都由人工注釋,并通過多年的工作進(jìn)行質(zhì)量控制。ImageNet 中的大多數(shù)同義詞集是名詞(80,000+),總共有超過 100,000 個(gè)同義詞集。因此,ImageNet 是一個(gè)組織良好的層次結(jié)構(gòu),可用于監(jiān)督機(jī)器學(xué)習(xí)任務(wù)。可以通過 ImageNet 網(wǎng)站注冊自己免費(fèi)訪問 ImageNet。借助龐大的圖像數(shù)據(jù)庫,研究人員可以隨意開發(fā)他們的算法。著名的 ImageNet 大規(guī)模視覺識別挑戰(zhàn)賽 (ILSVRC) 來了。這是 2010 年至 2017 年間舉辦的年度計(jì)算機(jī)視覺競賽。它也被稱為 ImageNet 挑戰(zhàn)賽。挑戰(zhàn)中的訓(xùn)練數(shù)據(jù)是 ImageNet 的一個(gè)子集:1,000 個(gè)同義詞集(類別)和 120 萬張圖像。這也就是我們常看到的ImageNet 1K或者說為什么我們看到的預(yù)訓(xùn)練模型的類別都是1000,這就是原因。什么是預(yù)訓(xùn)練模型?
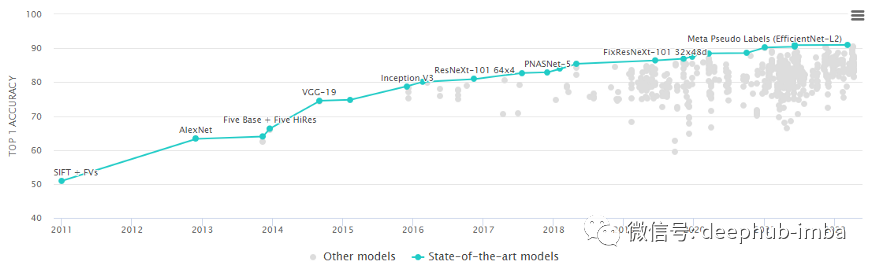
這個(gè)競賽激勵(lì)并獎(jiǎng)勵(lì)了許多出色的圖像分類模型。這些模型的訓(xùn)練都需要非常大規(guī)模、耗時(shí)且 CPU/GPU 密集型的計(jì)算。?每個(gè)模型都包含代表 ImageNet 中圖像特征的權(quán)重和偏差。它們被稱為預(yù)訓(xùn)練模型,因?yàn)槠渌芯咳藛T可以使用它們來解決類似的問題。下面讓我描述一些預(yù)訓(xùn)練模型的示例。
LeNet-5 (1989):經(jīng)典的 CNN 框架LeNet-5 是最早的卷積神經(jīng)網(wǎng)絡(luò)。該框架很簡單,因此許多類將其用作引入 CNN 的第一個(gè)模型。1989 年,Yann LeCun 等人。在貝爾實(shí)驗(yàn)室結(jié)合了一個(gè)由反向傳播算法訓(xùn)練的卷積神經(jīng)網(wǎng)絡(luò)來讀取手寫數(shù)字,并成功地將其應(yīng)用于識別美國郵政服務(wù)提供的手寫郵政編碼號碼。所以此處應(yīng)該有一張LeCun老師的照片 AlexNet 在 2012 年 ImageNet 挑戰(zhàn)賽中上臺,因?yàn)樗苑浅4蟮膬?yōu)勢獲勝。它實(shí)現(xiàn)了 17% 的top5錯(cuò)誤率,而第二名的錯(cuò)誤率為 26%。它的架構(gòu)與 LeNet-5 非常相似。它由 Alex Krizhevsky ,Ilya Sutskever ,以及Krizhevsky 的博士導(dǎo)師 Geoffrey Hinton 合作設(shè)計(jì)。?該模型有 6000 萬個(gè)參數(shù)和 500,000 個(gè)神經(jīng)元。可以將他看作是一個(gè)大號的LeNet。它是由 Christian Szegedy 等人開發(fā)的。來自谷歌研究。這個(gè)模型的參數(shù)比 AlexNet 少 10 倍,大約 600 萬。在牛津大學(xué)的 K. Simonyan 和 A. Zisserman 的帶領(lǐng)下,VGG-16 模型在他們的論文“Very Deep Convolutional Networks for Large-Scale Image Recognition”中提出。他們使用非常小的 (3x3) 卷積濾波器將深度增加到 16 層和 19 層。這種架構(gòu)顯示出顯著的改進(jìn)。VGG-16 名稱中的“16”指的是 CNN 的“16”層。它有大約 1.38 億個(gè)參數(shù)。顯然 VGG-19 比 VGG-16 大。VGG-19 只提供比 VGG-16 稍微好一些的精度,所以很多人使用 VGG-16。深度神經(jīng)網(wǎng)絡(luò)的層通常旨在學(xué)習(xí)盡可能多的特征。Kaiming He、Xiangyu Zhang、Shaoqing Ren、Jian Sun 在他們的論文“Deep Residual Learning for Image Recognition”中提出了一種新的架構(gòu)。他們提出了一個(gè)殘差學(xué)習(xí)框架。這些層被公式化為參考層輸入的學(xué)習(xí)殘差函數(shù),而不是學(xué)習(xí)未參考的函數(shù)。他們表明,這些殘差網(wǎng)絡(luò)更容易優(yōu)化,并且可以從顯著增加的深度中獲得準(zhǔn)確性。ResNet-50 中的“50”指的是 50 層。ResNet 模型在 ImageNet 挑戰(zhàn)賽中僅以 3.57% 的錯(cuò)誤率贏得了比賽。VIT等新技術(shù),想必大家也都熟悉了,這里就不多介紹了
AlexNet 在 2012 年 ImageNet 挑戰(zhàn)賽中上臺,因?yàn)樗苑浅4蟮膬?yōu)勢獲勝。它實(shí)現(xiàn)了 17% 的top5錯(cuò)誤率,而第二名的錯(cuò)誤率為 26%。它的架構(gòu)與 LeNet-5 非常相似。它由 Alex Krizhevsky ,Ilya Sutskever ,以及Krizhevsky 的博士導(dǎo)師 Geoffrey Hinton 合作設(shè)計(jì)。?該模型有 6000 萬個(gè)參數(shù)和 500,000 個(gè)神經(jīng)元。可以將他看作是一個(gè)大號的LeNet。它是由 Christian Szegedy 等人開發(fā)的。來自谷歌研究。這個(gè)模型的參數(shù)比 AlexNet 少 10 倍,大約 600 萬。在牛津大學(xué)的 K. Simonyan 和 A. Zisserman 的帶領(lǐng)下,VGG-16 模型在他們的論文“Very Deep Convolutional Networks for Large-Scale Image Recognition”中提出。他們使用非常小的 (3x3) 卷積濾波器將深度增加到 16 層和 19 層。這種架構(gòu)顯示出顯著的改進(jìn)。VGG-16 名稱中的“16”指的是 CNN 的“16”層。它有大約 1.38 億個(gè)參數(shù)。顯然 VGG-19 比 VGG-16 大。VGG-19 只提供比 VGG-16 稍微好一些的精度,所以很多人使用 VGG-16。深度神經(jīng)網(wǎng)絡(luò)的層通常旨在學(xué)習(xí)盡可能多的特征。Kaiming He、Xiangyu Zhang、Shaoqing Ren、Jian Sun 在他們的論文“Deep Residual Learning for Image Recognition”中提出了一種新的架構(gòu)。他們提出了一個(gè)殘差學(xué)習(xí)框架。這些層被公式化為參考層輸入的學(xué)習(xí)殘差函數(shù),而不是學(xué)習(xí)未參考的函數(shù)。他們表明,這些殘差網(wǎng)絡(luò)更容易優(yōu)化,并且可以從顯著增加的深度中獲得準(zhǔn)確性。ResNet-50 中的“50”指的是 50 層。ResNet 模型在 ImageNet 挑戰(zhàn)賽中僅以 3.57% 的錯(cuò)誤率贏得了比賽。VIT等新技術(shù),想必大家也都熟悉了,這里就不多介紹了遷移學(xué)習(xí)技術(shù)
人類善于學(xué)習(xí)知識并將知識轉(zhuǎn)移到類似的任務(wù)中。當(dāng)我們遇到新任務(wù)時(shí),我們會識別并應(yīng)用以前學(xué)習(xí)經(jīng)驗(yàn)中的相關(guān)知識。遷移學(xué)習(xí)技術(shù)是一項(xiàng)偉大的發(fā)明。它“轉(zhuǎn)移”在先前模型中學(xué)習(xí)的知識,以改進(jìn)當(dāng)前模型中的學(xué)習(xí)。考慮任何具有數(shù)百萬個(gè)參數(shù)的預(yù)訓(xùn)練模型。他們在模型參數(shù)中學(xué)習(xí)了圖像的特征。如果其他的任務(wù)相似,那么利用預(yù)訓(xùn)練模型中的知識(參數(shù))。遷移學(xué)習(xí)技術(shù)不需要重復(fù)訓(xùn)練大型模型的輪子,可以利用預(yù)訓(xùn)練模型來完成類似的任務(wù),并且可以依賴更少的數(shù)據(jù)。如果有一組新圖像并且需要構(gòu)建自己的圖像識別模型,可以在神經(jīng)網(wǎng)絡(luò)模型中包含一個(gè)預(yù)先訓(xùn)練好的模型。因此,遷移學(xué)習(xí)技術(shù)成為近年來的熱門話題。可以預(yù)見兩個(gè)研究前沿:(i)預(yù)訓(xùn)練模型將繼續(xù)發(fā)展,(ii)將產(chǎn)生越來越多的遷移學(xué)習(xí)模型以滿足特定需求。使用預(yù)訓(xùn)練模型識別未知圖像
在本節(jié)中,將展示如何使用 VGG-16 預(yù)訓(xùn)練模型來識別圖像,包括 (i) 如何加載圖像,(ii) 如何格式化預(yù)訓(xùn)練模型所需的圖像,以及 (iii) 如何應(yīng)用預(yù)訓(xùn)練模型。在圖像建模中,PyTorch 或 TensorFlow 或 Keras 已被研究人員廣泛使用。PyTorch 是 Facebook 的 AI 研究實(shí)驗(yàn)室基于 Torch 庫開發(fā)的基于 Python 的開源機(jī)器學(xué)習(xí)庫。由于其最大的靈活性和速度,它以深度學(xué)習(xí)計(jì)算而聞名。其應(yīng)用包括圖像識別、計(jì)算機(jī)視覺和自然語言處理。它是 NumPy 的替代品,可以使用 GPU 的強(qiáng)大運(yùn)算能力。Google 的 TensorFlow 是另一個(gè)著名的開源深度學(xué)習(xí)庫,用于跨一系列任務(wù)的數(shù)據(jù)流和可微分編程。PyTorch 或 TensorFlow 都非常適合 GPU 計(jì)算。PyTorch 在其庫中包含了許多預(yù)訓(xùn)練模型。從這個(gè)長長的 Pytorch 模型列表中選擇一個(gè)預(yù)訓(xùn)練模型。下面我選擇 VGG-16 并稱之為“vgg16”。import ioimport torchfrom PIL import Imageimport requestsfrom torch.autograd import Variableimport torchvision.models as modelsimport torchvision.transforms as transforms
vgg16 = models.vgg16(pretrained=True) vgg16
上面的第 10 行加載了 VGG-16 模型。可以將其打印出來以查看其架構(gòu),如下所示:如前所述,VGG-16 在 ImageNet 挑戰(zhàn)賽中使用了 1,000 個(gè)類別和 120 萬張圖像的訓(xùn)練。下面我將它保存到本地目錄“/downloads”并加載到一個(gè)名為“l(fā)abels”的列表中。
with open("/Downloads/imagenet_classes.txt", "r") as f: labels = [s.strip() for s in f.readlines()]
在下面的第 2 行中,我用搜索了“金魚”,并從圖片中隨機(jī)選擇了一張金魚圖片。在第 3 行中,我還搜索了老鷹,并隨機(jī)選擇了一張帶有圖片地址的老鷹圖片。import urlliburl, filename = ("https://cff2.earth.com/uploads/2022/01/06080341/Goldfish.jpg?raw=true", "goldfish.jpg")url, filename = ("https://cdn.britannica.com/92/152292-050-EAF28A45/Bald-eagle.jpg?raw=true", "eagle.jpg")
try: urllib.URLopener().retrieve(url, filename)except: urllib.request.urlretrieve(url, filename)
from PIL import Imagefrom torchvision import transformsinput_image = Image.open(filename).convert('RGB')print(input_image.size)input_image.show()
圖像可以由 Python Imaging Library(縮寫為 PIL,或稱為 Pillow 的較新版本)加載。第 13 行:圖像的大小為 (1600,1071)。這意味著圖像是一個(gè) 1,600 x 1,071 像素的文件。preprocess = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),])input_tensor = preprocess(input_image)input_tensor.shape input_batch = input_tensor.unsqueeze(0) input_tensor.shape
if torch.cuda.is_available(): input_batch = input_batch.to('cuda') model.to('cuda')
所有預(yù)訓(xùn)練模型都期望輸入圖像以相同的方式歸一化,即形狀為 (3 x H x W) 的 3 通道 RGB 圖像的小批量,其中 H 和 W 至少為 224。第 2、3 行:將圖像尺寸標(biāo)準(zhǔn)化為 [3,224,224]。第 5 行:使用 mean = [0.485, 0.456, 0.406] 和 std = [0.229, 0.224, 0.225] 對圖像進(jìn)行歸一化。output = vgg16(input_batch)
probabilities = torch.nn.functional.softmax(output[0], dim=0)
第1行是最重要的一步。它預(yù)測圖像是什么。輸出是包含 1,000 個(gè) ImageNet 同義詞集的 1,000 個(gè)值的列表。第 6 行:將 1,000 個(gè)值轉(zhuǎn)換為概率。top5_prob, top5_catid = torch.topk(probabilities, 5)for i in range(top5_prob.size(0)): print(labels[top5_catid[i]], top5_prob[i].item())
上面的代碼打印前五個(gè)概率和標(biāo)簽。我們輸入了一個(gè)鷹的形象。VGG-16 模型將圖像識別為“鷹”的概率為 0.9969。總結(jié)
這篇文章總結(jié)了圖像與訓(xùn)練模型的起源并且包含了一個(gè)使用的入門級示例,如果你對代碼感興趣,請?jiān)谶@里下載:https://github.com/dataman-git/codes_for_articles/blob/master/VGG-16.ipynb