
【關(guān)于 Attention 】那些你不知道的事
作者:楊夕
項(xiàng)目地址:https://github.com/km1994/nlp_paper_study
個(gè)人介紹:大佬們好,我叫楊夕,該項(xiàng)目主要是本人在研讀頂會(huì)論文和復(fù)現(xiàn)經(jīng)典論文過程中,所見、所思、所想、所聞,可能存在一些理解錯(cuò)誤,希望大佬們多多指正。
一、seq2seq 篇
1.1 seq2seq (Encoder-Decoder)是什么?
介紹:seq2seq (Encoder-Decoder)將一個(gè)句子(圖片)利用一個(gè) Encoder 編碼為一個(gè) context,然后在利用一個(gè) Decoder 將 context 解碼為 另一個(gè)句子(圖片)的過程 ;
應(yīng)用:
在 Image Caption 的應(yīng)用中 Encoder-Decoder 就是 CNN-RNN 的編碼 - 解碼框架;
在神經(jīng)網(wǎng)絡(luò)機(jī)器翻譯中 Encoder-Decoder 往往就是 LSTM-LSTM 的編碼 - 解碼框架,在機(jī)器翻譯中也被叫做 Sequence to Sequence learning。
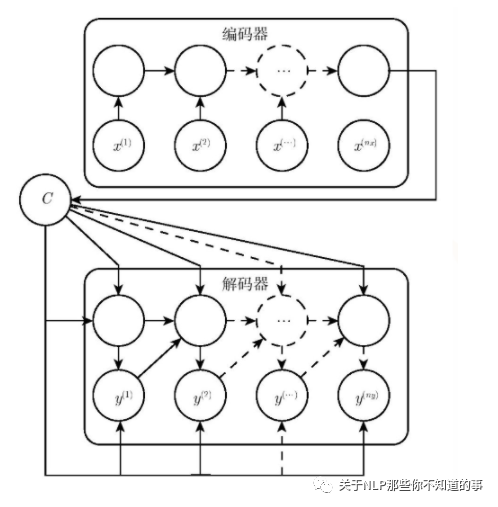
1.2 seq2seq 中 的 Encoder 怎么樣?
目標(biāo):將 input 編碼成一個(gè)固定長(zhǎng)度 語(yǔ)義編碼 context
context 作用:
1、做為初始向量初始化 Decoder 的模型,做為 decoder 模型預(yù)測(cè)y1的初始向量;
2、做為背景向量,指導(dǎo)y序列中每一個(gè)step的y的產(chǎn)出;
步驟:
遍歷輸入的每一個(gè)Token(詞),每個(gè)時(shí)刻的輸入是上一個(gè)時(shí)刻的隱狀態(tài)和輸入
會(huì)有一個(gè)輸出和新的隱狀態(tài)。這個(gè)新的隱狀態(tài)會(huì)作為下一個(gè)時(shí)刻的輸入隱狀態(tài)。每個(gè)時(shí)刻都有一個(gè)輸出;
保留最后一個(gè)時(shí)刻的隱狀態(tài),認(rèn)為它編碼了整個(gè)句子的 語(yǔ)義編碼 context,并把最后一個(gè)時(shí)刻的隱狀態(tài)作為Decoder的初始隱狀態(tài);
1.3 seq2seq 中 的 Decoder 怎么樣?
目標(biāo):將 語(yǔ)義編碼 context 解碼 為 一個(gè) 新的 output;
步驟:
一開始的隱狀態(tài)是Encoder最后時(shí)刻的隱狀態(tài),輸入是特殊的;
使用RNN計(jì)算新的隱狀態(tài),并輸出第一個(gè)詞;
接著用新的隱狀態(tài)和第一個(gè)詞計(jì)算第二個(gè)詞,直到decoder產(chǎn)生一個(gè) EOS token, 那么便結(jié)束輸出了;
1.4 在 數(shù)學(xué)角度上 的 seq2seq ,你知道么?
場(chǎng)景介紹:以 機(jī)器翻譯 為例,給定 一個(gè) 句子集合對(duì) <X,Y> (X 表示 一個(gè) 英文句子集合,Y 表示 一個(gè) 中文句子集合);
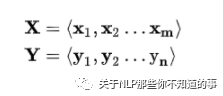
目標(biāo):對(duì)于 X 中 的 xi,我們需要采用 seq2seq 框架 來(lái) 生成 Y 中對(duì)應(yīng) 的 yi;
步驟:
編碼器 encoder:將 輸入 句子集合 X 進(jìn)行編碼,也就是將 其 通過 非線性變換 轉(zhuǎn)化為 中間語(yǔ)義編碼 Context C
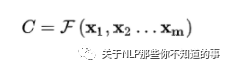
解碼器 decoder:對(duì)中間語(yǔ)義編碼 context 進(jìn)行解碼,根據(jù)句子 X 的中間語(yǔ)義編碼 Context C 和之前已經(jīng)生成的歷史信息 y1,y2,...,yi-1 生成 當(dāng)前時(shí)刻信息 yi
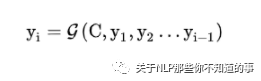
1.5 seq2seq 存在 什么 問題?
忽略了輸入序列X的長(zhǎng)度:當(dāng)輸入句子長(zhǎng)度很長(zhǎng),特別是比訓(xùn)練集中最初的句子長(zhǎng)度還長(zhǎng)時(shí),模型的性能急劇下降;
對(duì)輸入序列X缺乏區(qū)分度:輸入X編碼成一個(gè)固定的長(zhǎng)度,對(duì)句子中每個(gè)詞都賦予相同的權(quán)重,這樣做沒有區(qū)分度,往往是模型性能下降。
二、Attention 篇
2.1 什么是 Attention?
通俗易懂介紹:注意力機(jī)制模仿了生物觀察行為的內(nèi)部過程,即一種將內(nèi)部經(jīng)驗(yàn)和外部感覺對(duì)齊從而增加部分區(qū)域的觀察精細(xì)度的機(jī)制。例如人的視覺在處理一張圖片時(shí),會(huì)通過快速掃描全局圖像,獲得需要重點(diǎn)關(guān)注的目標(biāo)區(qū)域,也就是注意力焦點(diǎn)。然后對(duì)這一區(qū)域投入更多的注意力資源,以獲得更多所需要關(guān)注的目標(biāo)的細(xì)節(jié)信息,并抑制其它無(wú)用信息。
Attention 介紹:幫助模型對(duì)輸入的x每部分賦予不同的權(quán)重,抽取更重要的信息,使模型做出準(zhǔn)確判斷。同時(shí),不會(huì)給模型計(jì)算與存儲(chǔ)帶來(lái)更大開銷;
2.2 為什么引入 Attention機(jī)制?
根據(jù)通用近似定理,前饋網(wǎng)絡(luò)和循環(huán)網(wǎng)絡(luò)都有很強(qiáng)的能力。但為什么還要引入注意力機(jī)制呢?
計(jì)算能力的限制:當(dāng)要記住很多“信息“,模型就要變得更復(fù)雜,然而目前計(jì)算能力依然是限制神經(jīng)網(wǎng)絡(luò)發(fā)展的瓶頸。
優(yōu)化算法的限制:雖然局部連接、權(quán)重共享以及pooling等優(yōu)化操作可以讓神經(jīng)網(wǎng)絡(luò)變得簡(jiǎn)單一些,有效緩解模型復(fù)雜度和表達(dá)能力之間的矛盾;但是,如循環(huán)神經(jīng)網(wǎng)絡(luò)中的長(zhǎng)距離以來(lái)問題,信息“記憶”能力并不高。
2.3 Attention 有什么作用?
讓神經(jīng)網(wǎng)絡(luò)把 “ 注意力 ” 放在一部分輸入上,即:區(qū)分輸入的不同部分對(duì)輸出的影響;
從增強(qiáng)字 / 詞的語(yǔ)義表示這一角度介紹
一個(gè)字 / 詞在一篇文本中表達(dá)的意思通常與它的上下文有關(guān)。光看 “ 鵠 ” 字,我們可能會(huì)覺得很陌生(甚至連讀音是什幺都不記得吧),而看到它的上下文 “ 鴻鵠之志 ” 后,就對(duì)它立馬熟悉了起來(lái)。因此,字 / 詞的上下文信息有助于增強(qiáng)其語(yǔ)義表示。同時(shí),上下文中的不同字 / 詞對(duì)增強(qiáng)語(yǔ)義表示所起的作用往往不同。比如在上面這個(gè)例子中, “ 鴻 ” 字對(duì)理解 “ 鵠 ” 字的作用最大,而 “ 之 ” 字的作用則相對(duì)較小。為了有區(qū)分地利用上下文字信息增強(qiáng)目標(biāo)字的語(yǔ)義表示,就可以用到 Attention 機(jī)制。
2.4 Attention 流程是怎么樣?
步驟一 執(zhí)行encoder (與 seq2seq 一致)
思路:將源數(shù)據(jù)依次輸入Encoder,執(zhí)行Encoder
目標(biāo):將源序列的信息,編譯成語(yǔ)義向量,供后續(xù)decoder使用
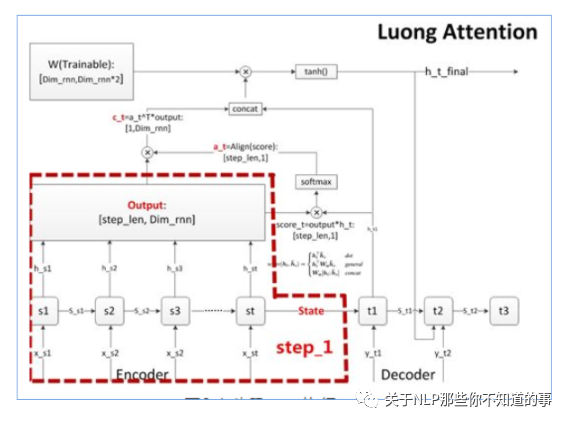
步驟二 計(jì)算對(duì)齊系數(shù) a
思路:在 decoder 的每個(gè)詞,我們需要關(guān)注源序列的所有詞和目標(biāo)序列當(dāng)前詞的相關(guān)性大小,并輸出相關(guān)(對(duì)齊)系數(shù) a;
步驟:
在decoder輸出一個(gè)預(yù)測(cè)值前,都會(huì)針對(duì)encoder的所有step,計(jì)算一個(gè)score;
將score匯總向量化后,每個(gè)decoder step能獲得一個(gè)維度為[step_len,1]的score向量;
計(jì)算出score后,很自然地按慣例使用softmax進(jìn)行歸一化,得到對(duì)齊向量a,維度也是[step_len,1];
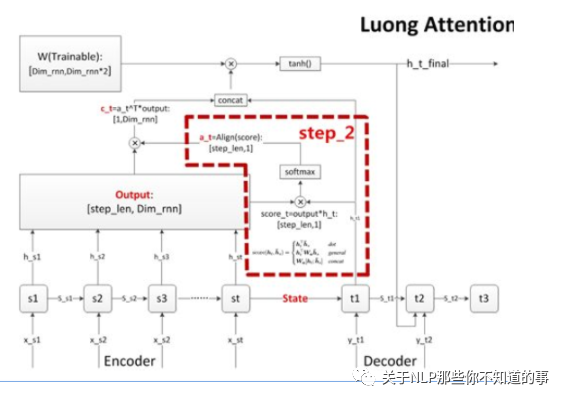
常用對(duì)齊函數(shù):

步驟三 計(jì)算上下文語(yǔ)義向量 C
思路:對(duì)齊系數(shù) a 作為權(quán)重,對(duì) encoder 每個(gè) step 的 output 向量進(jìn)行加權(quán)求和(對(duì)齊向量a點(diǎn)乘outputs矩陣),得到decoder當(dāng)前 step 的上下文語(yǔ)義向量 c
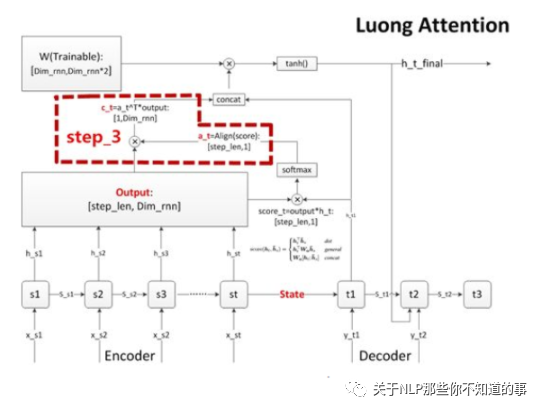
步驟四 更新decoder狀態(tài)
思路:更新decoder狀態(tài),這個(gè)狀態(tài)可以是h,也可以是 s
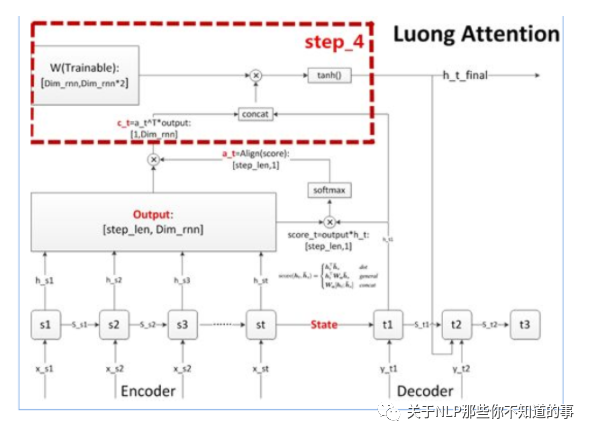
步驟五 計(jì)算輸出預(yù)測(cè)詞
思路:做一個(gè)語(yǔ)義向量到目標(biāo)詞表的映射(如果attention用于分類模型,那就是做一個(gè)到各個(gè)分類的映射),然后再進(jìn)行softmax就可以了
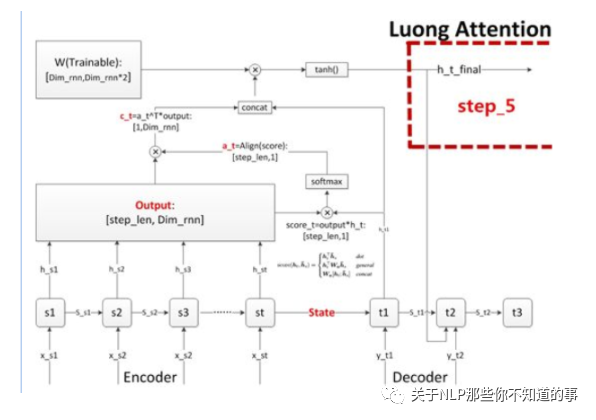
2.5 Attention 的應(yīng)用領(lǐng)域有哪些?
隨著 Attention 提出 開始,就被 廣泛 應(yīng)用于 各個(gè)領(lǐng)域。比如:自然語(yǔ)言處理,圖片識(shí)別,語(yǔ)音識(shí)別等不同方向深度學(xué)習(xí)任務(wù)中。隨著 【Transformer 】的提出,Attention被 推向了圣壇。
三、Attention 變體篇
3.1 Soft Attention 是什么?
Soft Attention:傳統(tǒng)的 Attention 方法,是參數(shù)化的(Parameterization),因此可導(dǎo),可以被嵌入到模型中去,直接訓(xùn)練。梯度可以經(jīng)過Attention Mechanism模塊,反向傳播到模型其他部分。
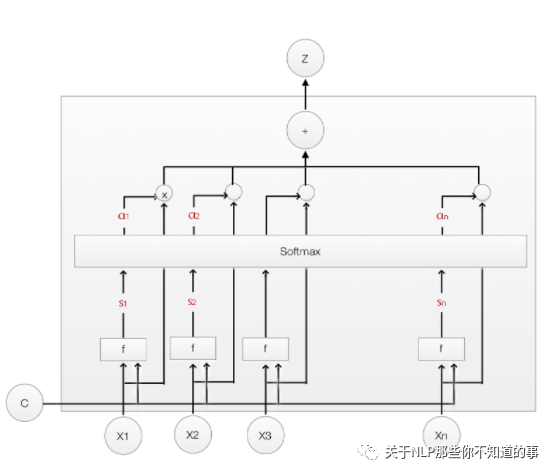
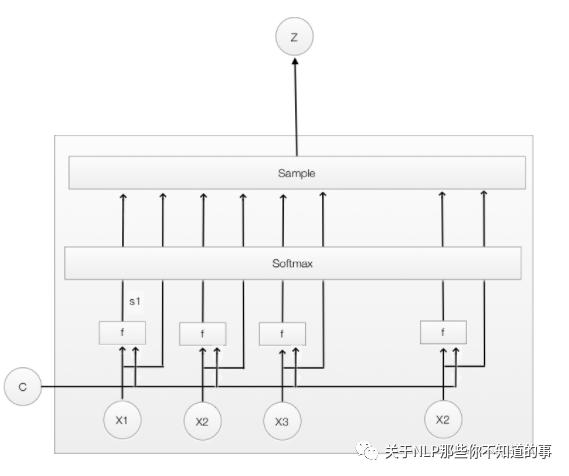
3.2 Hard Attention 是什么?
Hard Attention:一個(gè)隨機(jī)的過程。Hard Attention不會(huì)選擇整個(gè)encoder的輸出做為其輸入,Hard Attention會(huì)依概率Si來(lái)采樣輸入端的隱狀態(tài)一部分來(lái)進(jìn)行計(jì)算,而不是整個(gè)encoder的隱狀態(tài)。為了實(shí)現(xiàn)梯度的反向傳播,需要采用蒙特卡洛采樣的方法來(lái)估計(jì)模塊的梯度。
3.3 Global Attention 是什么?
Global Attention:傳統(tǒng)的Attention model一樣。所有的hidden state都被用于計(jì)算Context vector 的權(quán)重,即變長(zhǎng)的對(duì)齊向量at,其長(zhǎng)度等于encoder端輸入句子的長(zhǎng)度。
3.4 Local Attention 是什么?
動(dòng)機(jī):Global Attention 在做每一次 encoder 時(shí),encoder 中的所有 hidden state 都需要參與到計(jì)算中,這種方法容易造成 計(jì)算開銷增大,尤其是 句子偏長(zhǎng)的時(shí)候。
介紹:Local Attention 通過結(jié)合 Soft Attention 和 Hard Attention 的一種 Attention方法
3.5 self-attention 是什么?
核心思想:self-attention的結(jié)構(gòu)在計(jì)算每個(gè)token時(shí),總是會(huì)考慮整個(gè)序列其他token的表達(dá);舉例:“我愛中國(guó)”這個(gè)序列,在計(jì)算"我"這個(gè)詞的時(shí)候,不但會(huì)考慮詞本身的embedding,也同時(shí)會(huì)考慮其他詞對(duì)這個(gè)詞的影響
注:具體內(nèi)容可以參考 self-attention 長(zhǎng)怎么樣?
參考
【關(guān)于 Attention 】那些你不知道的事
nlp中的Attention注意力機(jī)制+Transformer詳解
模型匯總24 - 深度學(xué)習(xí)中Attention Mechanism詳細(xì)介紹:原理、分類及應(yīng)用