
【關于 新詞發(fā)現(xiàn)】那些你不知道的事
作者:楊夕
個人github:https://github.com/km1994/nlp_paper_study
NLP百面百搭:https://github.com/km1994/NLP-Interview-Notes
【注:手機閱讀可能圖片打不開!!!】
一、動機
網(wǎng)絡文檔和領域文檔文本的特點在于包含大量新詞,一般詞典的涵蓋程度比較低。對于領域文檔,各領域的專家可以人工構建知識本體,拓展已有詞庫的不健全,但是需要消耗大量的人力成本資源。
那么有沒有一種有效方法能夠發(fā)現(xiàn)上述兩種文本中的新詞呢?
二、 新詞發(fā)現(xiàn)模塊 有哪些階段?
新詞發(fā)現(xiàn)模塊 主要包含兩個階段:
離線階段:從海量文本語料中挖掘出高質(zhì)量的 短語及其屬性;
在線階段:識別給定文本中出現(xiàn)的 短語 供下游模塊使用。
三、 新詞發(fā)現(xiàn)模塊 的需求有哪些?
熱更新。相比于其他任務,由于網(wǎng)絡文檔和領域文檔的文本更新較快,所以新詞發(fā)現(xiàn)模塊需要持續(xù)積累和更新;
及時性。網(wǎng)絡文檔和領域文檔的文本更新后,新詞發(fā)現(xiàn)需要及時更新 資源庫,以滿足 任務需求。
四、 新詞發(fā)現(xiàn)模塊 的任務形式是怎么樣的?
phrase挖掘
輸入:一堆文本語料,輸出:語料中出現(xiàn)的phrase;
phrase識別
輸入:一段文本(query/title),輸出:文本中出現(xiàn)的phrase(需要消歧);
五、什么樣的新詞才屬于高質(zhì)量的新詞?
首先,看一下這個表格:
會發(fā)現(xiàn),新詞存在兩個特點:
構成形式無規(guī)律性。新詞構成形式比較開放,并無明顯規(guī)律可循;
類別多。新詞類別較多。
因此,什么樣的新詞才屬于高質(zhì)量的新詞呢?
從上述表格看出,高質(zhì)量的 新詞 需要滿足以下條件:
Popularity:候選phrase要有一定的熱度;(eg:“信息檢索”> “多語種信息檢索”)
Concordance:候選phrase的內(nèi)凝度應該比較高;(eg:“深度學習”> “學習分類器”)
Informative:候選phrase要包含一定的信息量,表示某個特定話題;(eg:“今天早晨”“該文中”雖然頻次很高,但不表示特定話題,信息量低)
Completeness:候選phrase相比于父(存在冗余)/子(不可切分)phrase更適合作為phrase;(eg:“幽門螺旋桿菌”>“幽門螺旋”)
六、新詞發(fā)現(xiàn)算法介紹
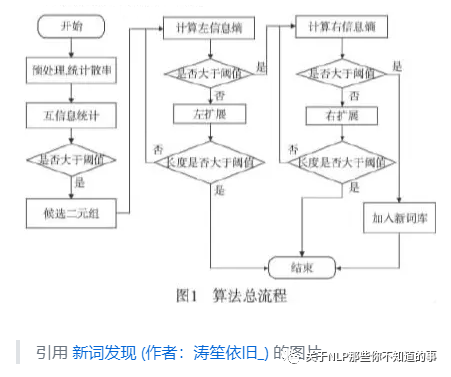
6.1 出現(xiàn)頻次
介紹:新詞在 段落中出現(xiàn)頻率往往比其他詞要高,所以當出現(xiàn)頻率越高,越有可能是新詞。
代碼實現(xiàn):
將 text 進行 n_gram
# 功能:將 text 進行 n_gram
def n_gram_words(self,text):
"""
功能:將 text 進行 n_gram
input:
text : String 輸入句子
return:
words_freq:Dict 詞頻 字典
"""
words = []
for i in range(1,self.n_gram+1):
words += [text[j:j+i] for j in range(len(text)-i+1)]
words_freq = dict(Counter(words))
new_words_freq = {}
for word,freq in words_freq.items():
new_words_freq[word]=freq
return new_words_freq
6.2 點間互信息(Pointwise Mutual Information)
動機:新詞一般在文本中出現(xiàn)頻率較高,但是出現(xiàn)頻率越高的詞并代表一定是新詞;
eg:“的電影”出現(xiàn)了 389 次,“電影院”只出現(xiàn)了 175 次,然而我們卻更傾向于把“電影院”當作一個詞,因為直覺上看,“電影”和“院”凝固得更緊一些。
思考:在出現(xiàn)頻率較高的候選新詞中,我們需要 計算 這些候選新詞的凝固程度,因為詞的內(nèi)部凝聚度越高,越容易成詞
做法:采用互信息計算方式,衡量知道一個詞之后另一個詞不確定性的減少程度。
公式:

結論:點間互信息越大,說明這兩個詞經(jīng)常出現(xiàn)在一起,意味著兩個詞的凝固程度越大,其組成一個新詞的可能性也就越大。
代碼實現(xiàn):
# 功能:PMI 過濾掉 噪聲詞
def PMI_filter(self, word_freq_dic):
"""
功能:PMI 過濾掉 噪聲詞
input:
words_freq:Dict 詞頻 字典
return:
new_words_dic:Dict PMI 過濾噪聲后 剩余新詞
"""
new_words_dic = {}
for word in word_freq_dic:
if len(word) == 1:
pass
else:
p_x_y = min([word_freq_dic.get(word[:i])* word_freq_dic.get(word[i:]) for i in range(1,len(word))])
mpi = p_x_y/word_freq_dic.get(word)
if mpi > self.min_p:
new_words_dic[word] = [mpi]
return new_words_dic
6.3 左右熵(Information Entropy)
動機:如果一個n-gram能夠算作一個phrase的話,它應該能夠靈活地出現(xiàn)在各種不同的環(huán)境中,具有非常豐富的左鄰字集合和右鄰字集合。左右搭配越豐富,越可能獨立成詞。
eg:“被子”和“輩子”右鄰字信息熵分別為3.87和4.11。而“被子”的左鄰字搭配卻豐富得多,有疊被子、蓋被子、搶被子、新被子、掀被子等等。“輩子”的左鄰字搭配則非常少,只有這輩子、八輩子、上輩子等。
做法:信息熵是一種衡量信息量大小的方式,熵越大,所含信息量越大,不確定性越高。因此可以分別計算n-gram的左鄰字信息熵和右鄰字信息熵,并取兩者的最小值。
公式:
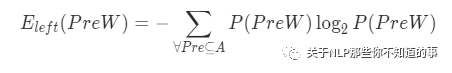
結論:左右熵值越大,說明該詞的周邊詞越豐富,意味著詞的自由程度越大,其成為一個獨立的詞的可能性也就越大。
代碼實現(xiàn):
計算字符列表的熵
# 功能:計算字符列表的熵
def calculate_entropy(self, char_list):
"""
功能:計算字符列表的熵
input:
char_list: List 字符列表
return:
entropy: float 熵
"""
char_freq_dic = dict(Counter(char_list))
entropy = (-1)*sum([ char_freq_dic.get(i)/len(char_list)*np.log2(char_freq_dic.get(i)/len(char_list)) for i in char_freq_dic])
return entropy
通過熵閾值從限定詞字典中過濾出最終的新詞
# 功能:通過熵閾值從限定詞字典中過濾出最終的新詞
def Entropy_left_right_filter(self,condinate_words_dic,text):
"""
功能:通過熵閾值從限定詞字典中過濾出最終的新詞
input:
condinate_words_dic:Dict 限定詞字典
text:String 句子
output:
final_words_list:List 最終的新詞列表
"""
final_words_list = []
for word in condinate_words_dic.keys():
left_right_char =re.findall('(.)%s(.)'%word,text)
left_char = [i[0] for i in left_right_char]
left_entropy = self.calculate_entropy(left_char)
right_char = [i[1] for i in left_right_char]
right_entropy = self.calculate_entropy(right_char)
score = condinate_words_dic[word][0]-min(left_entropy,right_entropy)
if min(right_entropy,left_entropy)> self.min_entropy and score<self.max_score and score>self.min_score:
final_words_list.append({
"word":word,
"pmi":condinate_words_dic[word][0],
"left_entropy":left_entropy,
"right_entropy":right_entropy,
"score":score
})
final_words_list = sorted(final_words_list, key=lambda x: x['score'], reverse=True)
return final_words_list
七、新詞發(fā)現(xiàn)代碼實現(xiàn)
7.1 導庫
from collections import Counter
import numpy as np
import re,os
import glob
import six
import codecs
import math
7.2 函數(shù)定義
7.2.1 停用詞加載
# 功能:停用詞加載
def get_stop_word(stop_word_path):
#停用詞列表,默認使用哈工大停用詞表
f = open(stop_word_path,encoding='utf-8')
stop_words = list()
for stop_word in f.readlines():
stop_words.append(stop_word[:-1])
return stop_words
7.2.2 語料生成器,并且初步預處理語料
# 語料生成器,并且初步預處理語料
def text_generator(file_path):
txts = glob.glob(f'{file_path}/*.txt')
for txt in txts:
d = codecs.open(txt, encoding='utf-8').read()
title = d.split("\n")[0]
d = d.replace(u'\u3000', '').strip()
yield title,re.sub(u'[^\u4e00-\u9fa50-9a-zA-Z ]+', '', d)
7.3 新詞發(fā)現(xiàn)類定義
class NewWordFind():
def __init__(self, n_gram=5, min_p=2 , min_entropy=1, max_score=100, min_score=2):
'''
input:
n_gram: int n_gram 的 粒度
min_p: int 最小 信息熵 閾值
min_entropy: int 左右熵 閾值
max_score: int 綜合得分最大閾值
min_score: int 綜合得分最小閾值
'''
self.n_gram = n_gram
self.min_p = min_p
self.min_entropy = min_entropy
self.max_score = max_score
self.min_score = min_score
# 功能:將 text 進行 n_gram
def n_gram_words(self,text):
"""
功能:將 text 進行 n_gram
input:
text : String 輸入句子
return:
words_freq:Dict 詞頻 字典
"""
words = []
for i in range(1,self.n_gram+1):
words += [text[j:j+i] for j in range(len(text)-i+1)]
words_freq = dict(Counter(words))
new_words_freq = {}
for word,freq in words_freq.items():
new_words_freq[word]=freq
return new_words_freq
# 功能:PMI 過濾掉 噪聲詞
def PMI_filter(self, word_freq_dic):
"""
功能:PMI 過濾掉 噪聲詞
input:
words_freq:Dict 詞頻 字典
return:
new_words_dic:Dict PMI 過濾噪聲后 剩余新詞
"""
new_words_dic = {}
for word in word_freq_dic:
if len(word) == 1:
pass
else:
p_x_y = min([word_freq_dic.get(word[:i])* word_freq_dic.get(word[i:]) for i in range(1,len(word))])
mpi = p_x_y/word_freq_dic.get(word)
if mpi > self.min_p:
new_words_dic[word] = [mpi]
return new_words_dic
# 功能:計算字符列表的熵
def calculate_entropy(self, char_list):
"""
功能:計算字符列表的熵
input:
char_list: List 字符列表
return:
entropy: float 熵
"""
char_freq_dic = dict(Counter(char_list))
entropy = (-1)*sum([ char_freq_dic.get(i)/len(char_list)*np.log2(char_freq_dic.get(i)/len(char_list)) for i in char_freq_dic])
return entropy
# 功能:通過熵閾值從限定詞字典中過濾出最終的新詞
def Entropy_left_right_filter(self,condinate_words_dic,text):
"""
功能:通過熵閾值從限定詞字典中過濾出最終的新詞
input:
condinate_words_dic:Dict 限定詞字典
text:String 句子
output:
final_words_list:List 最終的新詞列表
"""
final_words_list = []
for word in condinate_words_dic.keys():
left_right_char =re.findall('(.)%s(.)'%word,text)
left_char = [i[0] for i in left_right_char]
left_entropy = self.calculate_entropy(left_char)
right_char = [i[1] for i in left_right_char]
right_entropy = self.calculate_entropy(right_char)
score = condinate_words_dic[word][0]-min(left_entropy,right_entropy)
if min(right_entropy,left_entropy)> self.min_entropy and score<self.max_score and score>self.min_score:
final_words_list.append({
"word":word,
"pmi":condinate_words_dic[word][0],
"left_entropy":left_entropy,
"right_entropy":right_entropy,
"score":score
})
final_words_list = sorted(final_words_list, key=lambda x: x['score'], reverse=True)
return final_words_list
7.4 新詞發(fā)現(xiàn)類 測試
# read the data and preprocessing the data to a whole str
stop_word= get_stop_word("resource/stopword.txt")
file_path = "data/"
n_gram = 5
min_p = 2
min_entropy = 1
max_score = 100
min_score = 2
new_word_find = NewWordFind( n_gram=n_gram, min_p=min_p , min_entropy=min_entropy, max_score=max_score, min_score=min_score)
for index,(title,text) in enumerate(text_generator(file_path)):
print(f"\n index :{index} => title:{title}")
for i in stop_word:
text=text.replace(i,"")
n_gram = new_word_find.n_gram_words(text)
new_words_dic = new_word_find.PMI_filter(n_gram)
new_words_list = new_word_find.Entropy_left_right_filter(new_words_dic,text)
for new_words in new_words_list:
print(f"{new_words}")
7.5 新詞發(fā)現(xiàn)結果展示
index :0 => title:##習近平在第六屆東方經(jīng)濟論壇全會開幕式上的致辭(全文)
{'word': '方面', 'pmi': 18.666666666666668, 'left_entropy': 1.584962500721156, 'right_entropy': 1.584962500721156, 'score': 17.08170416594551}
{'word': '合作', 'pmi': 13.75, 'left_entropy': 3.0, 'right_entropy': 3.0, 'score': 10.75}
{'word': '中國', 'pmi': 12.0, 'left_entropy': 1.584962500721156, 'right_entropy': 1.584962500721156, 'score': 10.415037499278844}
{'word': '中俄', 'pmi': 6.0, 'left_entropy': 1.584962500721156, 'right_entropy': 1.584962500721156, 'score': 4.415037499278844}
{'word': '發(fā)展', 'pmi': 5.0, 'left_entropy': 1.584962500721156, 'right_entropy': 1.584962500721156, 'score': 3.415037499278844}
{'word': '世界', 'pmi': 5.0, 'left_entropy': 2.321928094887362, 'right_entropy': 2.321928094887362, 'score': 2.678071905112638}
參考
基于互信息和左右熵的新詞發(fā)現(xiàn)算法——python實現(xiàn)
學習NLP的第20天——基于信息熵和互信息的新詞提取實現(xiàn)_數(shù)據(jù)藝術家-程序員宅基地
反作弊基于左右信息熵和互信息的新詞挖掘
重新寫了之前的新詞發(fā)現(xiàn)算法:更快更好的新詞發(fā)現(xiàn)
新詞發(fā)現(xiàn)