
清華 CVer 對自監(jiān)督學(xué)習(xí)的一些思考
點(diǎn)擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時間送達(dá)
推薦閱讀



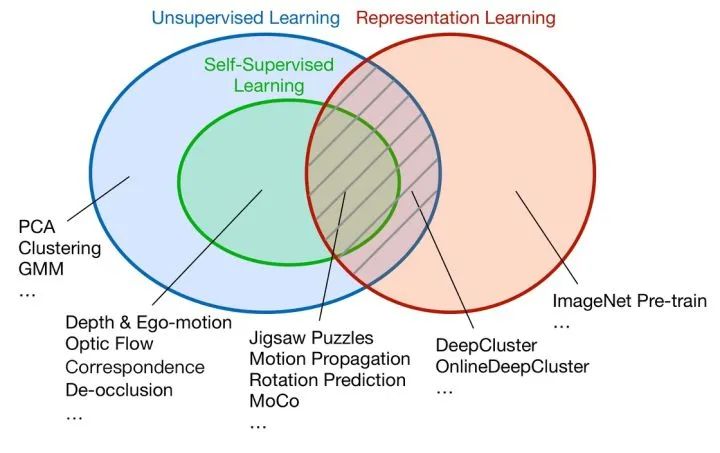
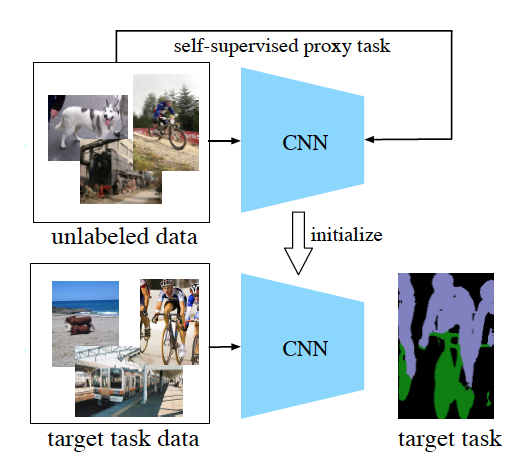

 為什么自監(jiān)督學(xué)習(xí)能學(xué)到新信息 ?
為什么自監(jiān)督學(xué)習(xí)能學(xué)到新信息 ?
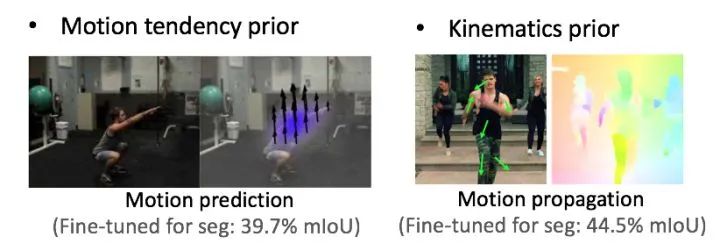

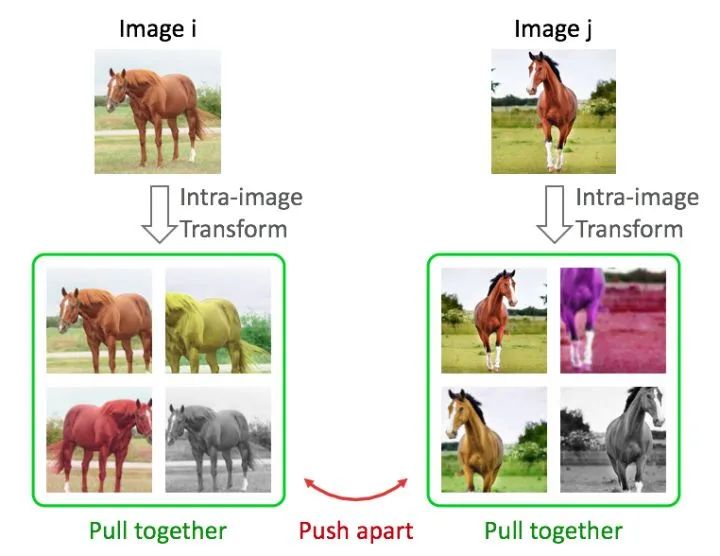
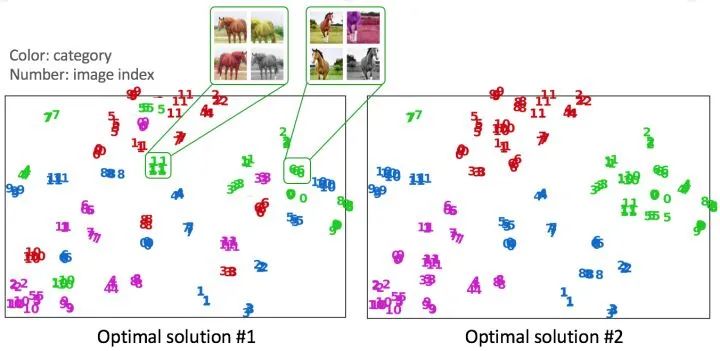
 設(shè)計(jì)一個自監(jiān)督學(xué)習(xí)任務(wù)還需要考慮什么?
設(shè)計(jì)一個自監(jiān)督學(xué)習(xí)任務(wù)還需要考慮什么?


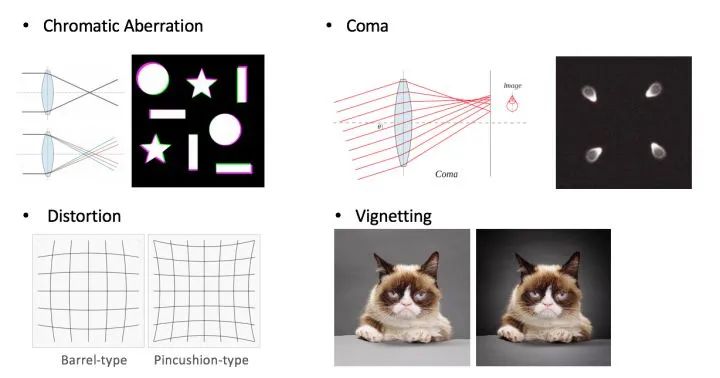

 展望
展望
本文已由原作者授權(quán),不得擅自二次轉(zhuǎn)載。 https://zhuanlan.zhihu.com/p/150224914
Pathak, Deepak, et al. "Context encoders: Feature learning by inpainting."Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
Walker, Jacob, Abhinav Gupta, and Martial Hebert. "Dense optical flow prediction from a static image."Proceedings of the IEEE International Conference on Computer Vision. 2015.
Noroozi, Mehdi, and Paolo Favaro. "Unsupervised learning of visual representations by solving jigsaw puzzles."European Conference on Computer Vision. Springer, Cham, 2016.
Misra, Ishan, C. Lawrence Zitnick, and Martial Hebert. "Shuffle and learn: unsupervised learning using temporal order verification."European Conference on Computer Vision. Springer, Cham, 2016.
Wu, Zhirong, et al. "Unsupervised feature learning via non-parametric instance discrimination."Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
Grill, Jean-Bastien, et al. "Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning."arXiv preprint arXiv:2006.07733(2020).

交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計(jì)算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會逐漸細(xì)分),請掃描下面微信號加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進(jìn)入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~