
【關(guān)于 關(guān)鍵詞提取】 那些你不知道的事
作者:楊夕
項(xiàng)目地址:https://github.com/km1994/nlp_paper_study
個(gè)人介紹:大佬們好,我叫楊夕,該項(xiàng)目主要是本人在研讀頂會(huì)論文和復(fù)現(xiàn)經(jīng)典論文過程中,所見、所思、所想、所聞,可能存在一些理解錯(cuò)誤,希望大佬們多多指正。

【關(guān)于 關(guān)鍵詞提取】 那些你不知道的事
一、TF-IDF關(guān)鍵詞提取算法
1.1 理論基礎(chǔ)
1.2 計(jì)算公式
1.2.1 詞頻 (Term Frequency,TF)
1.2.2 逆文本頻率(Inverse Document Frequency,IDF)
1.2.3 TF-IDF
1.3 應(yīng)用
1.4 實(shí)戰(zhàn)篇
1.4.1 TF-IDF算法 手?jǐn)]版
1.4.2 TF-IDF算法 Sklearn 版
1.4.3 TF-IDF算法 jieba 版
二、PageRank算法【1】
2.1 理論學(xué)習(xí)
三、TextRank算法【2】
3.1 理論學(xué)習(xí)
3.2 實(shí)戰(zhàn)篇
3.2.1 基于Textrank4zh的TextRank算法版
3.2.2 基于jieba的TextRank算法實(shí)現(xiàn)
3.2.3 基于SnowNLP的TextRank算法實(shí)現(xiàn)
參考
一、TF-IDF關(guān)鍵詞提取算法
1.1 理論基礎(chǔ)
類型:一種統(tǒng)計(jì)方法
作用:用以評(píng)估句子中的某一個(gè)詞(字)對(duì)于整個(gè)文檔的重要程度;
重要程度的評(píng)估:
對(duì)于 句子中的某一個(gè)詞(字)隨著其在整個(gè)句子中的出現(xiàn)次數(shù)的增加,其重要性也隨著增加;(正比關(guān)系)【體現(xiàn)詞在句子中頻繁性】
對(duì)于 句子中的某一個(gè)詞(字)隨著其在整個(gè)文檔中的出現(xiàn)頻率的增加,其重要性也隨著減少;(反比關(guān)系)【體現(xiàn)詞在文檔中的唯一性】
重要思想:
如果某個(gè)單詞在一篇文章中出現(xiàn)的頻率TF高,并且在其他文章中很少出現(xiàn),則認(rèn)為此詞或者短語具有很好的類別區(qū)分能力,適合用來分類;
1.2 計(jì)算公式
1.2.1 詞頻 (Term Frequency,TF)
介紹:體現(xiàn) 詞 在 句子 中出現(xiàn)的頻率;
問題:
需要做歸一化(詞頻除以句子總字?jǐn)?shù))
當(dāng)一個(gè)句子長(zhǎng)度的增加,句子中 每一個(gè) 出現(xiàn)的次數(shù) 也會(huì)隨之增加,導(dǎo)致該值容易偏向長(zhǎng)句子;
解決方法:
公式

1.2.2 逆文本頻率(Inverse Document Frequency,IDF)
介紹:體現(xiàn) 詞 在文檔 中出現(xiàn)的頻率
方式:某一特定詞語的IDF,可以由總句子數(shù)目除以包含該詞語的句子的數(shù)目,再將得到的商取對(duì)數(shù)得到;
作用:如果包含詞條t的文檔越少, IDF越大,則說明詞條具有很好的類別區(qū)分能力
公式:
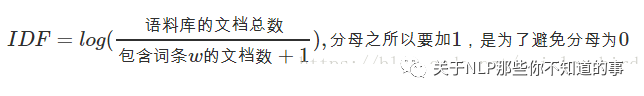
1.2.3 TF-IDF
介紹:某一特定句子內(nèi)的高詞語頻率,以及該詞語在整個(gè)文檔集合中的低文檔頻率,可以產(chǎn)生出高權(quán)重的TF-IDF。因此,TF-IDF傾向于過濾掉常見的詞語,保留重要的詞語。
優(yōu)點(diǎn):
容易理解;
容易實(shí)現(xiàn);
缺點(diǎn):
其簡(jiǎn)單結(jié)構(gòu)并沒有考慮詞語的語義信息,無法處理一詞多義與一義多詞的情況
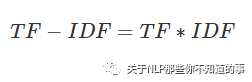
1.3 應(yīng)用
搜索引擎;
關(guān)鍵詞提取;
文本相似性;
文本摘要
1.4 實(shí)戰(zhàn)篇
1.4.1 TF-IDF算法 手?jǐn)]版
TF-idf 函數(shù)復(fù)現(xiàn)
# 函數(shù)說明:特征選擇TF-IDF算法
def tfidf_feature_select(list_words):
"""
函數(shù)說明:特征選擇TF-IDF算法
Parameters:
list_words:詞列表
Returns:
dict_feature_select:特征選擇詞字典
"""
sent_keyword_list = []
for word_list in list_words:
#總詞頻統(tǒng)計(jì)
doc_frequency=defaultdict(int)
for i in word_list:
doc_frequency[i]+=1
#計(jì)算每個(gè)詞的TF值
word_tf={} #存儲(chǔ)沒個(gè)詞的tf值
for i in doc_frequency:
word_tf[i]=doc_frequency[i]/sum(doc_frequency.values())
#計(jì)算每個(gè)詞的IDF值
doc_num=len(list_words)
word_idf={} #存儲(chǔ)每個(gè)詞的idf值
word_doc=defaultdict(int) #存儲(chǔ)包含該詞的文檔數(shù)
for i in doc_frequency:
for j in list_words:
if i in j:
word_doc[i]+=1
for i in doc_frequency:
word_idf[i]=math.log(doc_num/(word_doc[i]+1))
#計(jì)算每個(gè)詞的TF*IDF的值
word_tf_idf={}
for i in doc_frequency:
word_tf_idf[i]=word_tf[i]*word_idf[i]
# 對(duì)字典按值由大到小排序
dict_feature_select=sorted(word_tf_idf.items(),key=operator.itemgetter(1),reverse=True)
sent_keyword_list.append(dict_feature_select[0:5])
return sent_keyword_list
函數(shù)調(diào)用
print(f"docs[0:1]:{docs[0:1]}")
>>>
[['中國(guó)', '本周', '新冠', '疫情', '中國(guó)', '包括', '北京', '疫情', '本周', '北京', '中國(guó)', '當(dāng)局']]
features=tfidf_feature_select(docs) #所有詞的TF-IDF值
print(len(features))
for feature in features:
print(feature)
>>>
100
[('北京', 0.44321000615546297), ('本周', 0.3837641821656743), ('疫情', 0.2767885344702751), ('中國(guó)', 0.24856306833596672), ('當(dāng)局', 0.23445089306333636)]
[('香港', 0.8666204143875924), ('本周', 0.26568289534546685), ('反對(duì)', 0.19428681879294274), ('BBC', 0.16979037793767088), ('回應(yīng)', 0.10227923218972224)]
[('點(diǎn)', 0.6743380571769196), ('本周', 0.17712193023031123), ('經(jīng)濟(jì)', 0.17712193023031123), ('疫情', 0.12774855437089622), ('7', 0.12004982678958988)]
[('爆發(fā)', 0.21022682621431513), ('香港', 0.16941451709832633), ('北京', 0.13996105457540936), ('月', 0.10754223658231381), ('氣溶膠', 0.10511341310715756)]
[('當(dāng)局', 0.29614849650105646), ('6', 0.1748138112443843), ('不明', 0.15767011966073635), ('爆發(fā)', 0.15767011966073635), ('事件', 0.15767011966073635)]
...
1.4.2 TF-IDF算法 Sklearn 版
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
docs_list = [" ".join(doc) for doc in docs]
#該類會(huì)統(tǒng)計(jì)每個(gè)詞語的tf-idf權(quán)值
tf_idf_Vectorizer = TfidfVectorizer()
#將文本轉(zhuǎn)為詞頻矩陣并計(jì)算tf-idf
tfidf_mat = tf_idf_Vectorizer.fit_transform(docs_list)
vocab_dict =tf_idf_Vectorizer.vocabulary_#獲得所有文本的關(guān)鍵字和其位置的dict
#將tf-idf矩陣抽取出來,元素a[i][j]表示j詞在i類文本中的tf-idf權(quán)重
weight = tfidf_mat.toarray()
feat = np.argsort(-weight)#降序排序
total_key_word = []
for l in range(len(docs_list)):
values_word = []
for j in range(5):#獲取每類文本的5個(gè)關(guān)鍵字
keyword = [k for k,v in vocab_dict.items() if v ==feat[l,j]]
values_word.append(keyword[0])
total_key_word.append(values_word)
for key_word in total_key_word:
print(key_word)
>>>
['北京', '本周', '中國(guó)', '疫情', '當(dāng)局']
['香港', '本周', '反對(duì)', 'bbc', '回應(yīng)']
['本周', '經(jīng)濟(jì)', '中國(guó)', '疫情', '支持']
['爆發(fā)', '香港', '北京', '病毒', '疫情']
['當(dāng)局', '中國(guó)', '事件', '爆發(fā)', '不明']
...
1.4.3 TF-IDF算法 jieba 版
import jieba.analyse
text='關(guān)鍵詞是能夠表達(dá)文檔中心內(nèi)容的詞語,常用于計(jì)算機(jī)系統(tǒng)標(biāo)引論文內(nèi)容特征、信息檢索、系統(tǒng)匯集以供讀者檢閱。關(guān)鍵詞提取是文本挖掘領(lǐng)域的一個(gè)分支,是文本檢索、文檔比較、摘要生成、文檔分類和聚類等文本挖掘研究的基礎(chǔ)性工作'
for doc in docs_list:
keywords=jieba.analyse.extract_tags(doc, topK=5, withWeight=True, allowPOS=())
print(keywords)
>>>
[('疫情', 1.3477578533583332), ('新冠', 0.9962306252416666), ('本周', 0.972621126705), ('北京', 0.7779003847866667), ('中國(guó)', 0.756830171665)]
[('香港', 1.6952004552875), ('BBC', 0.9962306252416666), ('本周', 0.72946584502875), ('反對(duì)', 0.46703171161083334), ('回應(yīng)', 0.3104253012429167)]
[('疫情', 1.0782062826866665), ('新冠', 0.7969845001933333), ('BBC', 0.7969845001933333), ('本周', 0.778096901364), ('中國(guó)', 0.605464137332)]
[('新冠', 0.9195975002230768), ('疫情', 0.6220420861653846), ('爆發(fā)', 0.607387069014359), ('病毒', 0.5705823308092308), ('氣溶膠', 0.5367533562820512)]
...
二、PageRank算法【1】
2.1 理論學(xué)習(xí)
論文:The PageRank Citation Ranking: Bringing Order to the Web
介紹:通過計(jì)算網(wǎng)頁鏈接的數(shù)量和質(zhì)量來粗略估計(jì)網(wǎng)頁的重要性,算法創(chuàng)立之初即應(yīng)用在谷歌的搜索引擎中,對(duì)網(wǎng)頁進(jìn)行排名;
核心思想:
鏈接數(shù)量:如果一個(gè)網(wǎng)頁被越多的其他網(wǎng)頁鏈接,說明這個(gè)網(wǎng)頁越重要,即該網(wǎng)頁的PR值(PageRank值)會(huì)相對(duì)較高;
鏈接質(zhì)量:如果一個(gè)網(wǎng)頁被一個(gè)越高權(quán)值的網(wǎng)頁鏈接,也能表明這個(gè)網(wǎng)頁越重要,即一個(gè)PR值很高的網(wǎng)頁鏈接到一個(gè)其他網(wǎng)頁,那么被鏈接到的網(wǎng)頁的PR值會(huì)相應(yīng)地因此而提高;
計(jì)算公式
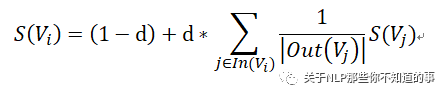
S(V_i) :網(wǎng)頁 i 的 重要性;
d:托尼系數(shù);
ln(V_i):整個(gè)互聯(lián)網(wǎng)中所存在的有指向網(wǎng)頁 i 的鏈接的網(wǎng)頁集合;
Out(V_j):網(wǎng)頁 j 中存在的指向所有外部網(wǎng)頁的鏈接的集合;
Out(V_j):該集合中元素的個(gè)數(shù);
三、TextRank算法【2】
3.1 理論學(xué)習(xí)
論文:TextRank: Bringing Order into Texts
介紹:一種基于圖的用于關(guān)鍵詞抽取和文檔摘要的排序算法,由谷歌的網(wǎng)頁重要性排序算法PageRank算法改進(jìn)而來,它利用一篇文檔內(nèi)部的詞語間的共現(xiàn)信息(語義)便可以抽取關(guān)鍵詞,它能夠從一個(gè)給定的文本中抽取出該文本的關(guān)鍵詞、關(guān)鍵詞組,并使用抽取式的自動(dòng)文摘方法抽取出該文本的關(guān)鍵句;
基本思想:將文檔看作一個(gè)詞的網(wǎng)絡(luò),該網(wǎng)絡(luò)中的鏈接表示詞與詞之間的語義關(guān)系;
計(jì)算公式:
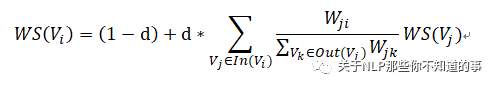
pageRank vs TextRank
PageRank算法根據(jù)網(wǎng)頁之間的鏈接關(guān)系構(gòu)造網(wǎng)絡(luò),TextRank算法根據(jù)詞之間的共現(xiàn)關(guān)系構(gòu)造網(wǎng)絡(luò);
PageRank算法構(gòu)造的網(wǎng)絡(luò)中的邊是有向無權(quán)邊,TextRank算法構(gòu)造的網(wǎng)絡(luò)中的邊是無向有權(quán)邊。
3.2 實(shí)戰(zhàn)篇
3.2.1 基于Textrank4zh的TextRank算法版
函數(shù)
from textrank4zh import TextRank4Keyword, TextRank4Sentence
import pandas as pd
import numpy as np
# 功能:關(guān)鍵詞抽取
def keywords_extraction(text):
'''
功能:關(guān)鍵詞抽取
'''
tr4w = TextRank4Keyword(allow_speech_tags=['n', 'nr', 'nrfg', 'ns', 'nt', 'nz'])
# allow_speech_tags --詞性列表,用于過濾某些詞性的詞
tr4w.analyze(text=text, window=2, lower=True, vertex_source='all_filters', edge_source='no_stop_words',
pagerank_config={'alpha': 0.85, })
# text -- 文本內(nèi)容,字符串
# window -- 窗口大小,int,用來構(gòu)造單詞之間的邊。默認(rèn)值為2
# lower -- 是否將英文文本轉(zhuǎn)換為小寫,默認(rèn)值為False
# vertex_source -- 選擇使用words_no_filter, words_no_stop_words, words_all_filters中的哪一個(gè)來構(gòu)造pagerank對(duì)應(yīng)的圖中的節(jié)點(diǎn)
# -- 默認(rèn)值為`'all_filters'`,可選值為`'no_filter', 'no_stop_words', 'all_filters'
# edge_source -- 選擇使用words_no_filter, words_no_stop_words, words_all_filters中的哪一個(gè)來構(gòu)造pagerank對(duì)應(yīng)的圖中的節(jié)點(diǎn)之間的邊
# -- 默認(rèn)值為`'no_stop_words'`,可選值為`'no_filter', 'no_stop_words', 'all_filters'`。邊的構(gòu)造要結(jié)合`window`參數(shù)
# pagerank_config -- pagerank算法參數(shù)配置,阻尼系數(shù)為0.85
keywords = tr4w.get_keywords(num=6, word_min_len=2)
# num -- 返回關(guān)鍵詞數(shù)量
# word_min_len -- 詞的最小長(zhǎng)度,默認(rèn)值為1
return keywords
# 功能:關(guān)鍵短語抽取
def keyphrases_extraction(text):
'''
功能:關(guān)鍵短語抽取
'''
tr4w = TextRank4Keyword()
tr4w.analyze(text=text, window=2, lower=True, vertex_source='all_filters', edge_source='no_stop_words',
pagerank_config={'alpha': 0.85, })
keyphrases = tr4w.get_keyphrases(keywords_num=6, min_occur_num=1)
# keywords_num -- 抽取的關(guān)鍵詞數(shù)量
# min_occur_num -- 關(guān)鍵短語在文中的最少出現(xiàn)次數(shù)
return keyphrases
# 功能:關(guān)鍵句抽取
def keysentences_extraction(text):
'''
功能:關(guān)鍵句抽取
'''
tr4s = TextRank4Sentence()
tr4s.analyze(text, lower=True, source='all_filters')
# text -- 文本內(nèi)容,字符串
# lower -- 是否將英文文本轉(zhuǎn)換為小寫,默認(rèn)值為False
# source -- 選擇使用words_no_filter, words_no_stop_words, words_all_filters中的哪一個(gè)來生成句子之間的相似度。
# -- 默認(rèn)值為`'all_filters'`,可選值為`'no_filter', 'no_stop_words', 'all_filters'
# sim_func -- 指定計(jì)算句子相似度的函數(shù)
# 獲取最重要的num個(gè)長(zhǎng)度大于等于sentence_min_len的句子用來生成摘要
keysentences = tr4s.get_key_sentences(num=3, sentence_min_len=6)
return keysentences
函數(shù)調(diào)用
for text in origin_docs:
#關(guān)鍵詞抽取
keywords=keywords_extraction(text)
print(keywords)
#關(guān)鍵短語抽取
keyphrases=keyphrases_extraction(text)
print(keyphrases)
#關(guān)鍵句抽取
keysentences=keysentences_extraction(text)
print(keysentences)
>>>
[{'word': '香港', 'weight': 0.1285260989050496}, {'word': '移民', 'weight': 0.07779005833762835}, {'word': '入籍', 'weight': 0.05570067956084056}, {'word': '法律', 'weight': 0.04878048780487805}, {'word': '重點(diǎn)', 'weight': 0.04878048780487805}, {'word': '護(hù)照', 'weight': 0.04878048780487805}]
['香港移民']
[{'index': 2, 'sentence': '西方國(guó)家對(duì)香港《國(guó)安法》反應(yīng)強(qiáng)烈,此前英國(guó)承諾為香港BNO護(hù)照持有者開啟移民入籍路徑,本周BBC中文采訪探討這一政策是否會(huì)導(dǎo)致香港移民潮', 'weight': 0.26955405823175094}, {'index': 3, 'sentence': '本周澳大利亞政府也推出一系列措施,作為回應(yīng),包括暫停與香港的引渡協(xié)議、更新旅游建議以及為香港居民提供簽證便利等', 'weight': 0.20413024124428358}, {'index': 4, 'sentence': '中國(guó)則對(duì)兩國(guó)的干涉表示反對(duì),稱澳方成天把反對(duì)"外國(guó)干涉"掛在嘴邊,卻在涉港問題上說三道四,充分暴露了其虛偽性和雙重標(biāo)準(zhǔn)', 'weight': 0.2}]
...
3.2.2 基于jieba的TextRank算法實(shí)現(xiàn)
方法介紹
import jieba.analyse
def keywords_textrank(text):
keywords = jieba.analyse.textrank(text, topK=6)
return keywords
for text in origin_docs:
#關(guān)鍵詞抽取
keywords=keywords_textrank(text)
print(keywords)
>>>
['中國(guó)', '北京', '疫情', '公平性', '股市', '高考']
['香港', '移民', '虛偽性', '干涉', '相關(guān)', '機(jī)構(gòu)']
['經(jīng)濟(jì)', '中國(guó)', '股市', '暴漲', '疫情', '上漲']
['病毒', '新冠', '爆發(fā)', '北京', '氣溶膠', '傳播']
['中國(guó)', '當(dāng)局', '文章', '帶走', '疫情', '知識(shí)分子']
...
3.2.3 基于SnowNLP的TextRank算法實(shí)現(xiàn)
from snownlp import SnowNLP
for text in origin_docs:
# 基于SnowNLP的textrank算法實(shí)現(xiàn)
snlp=SnowNLP(text)
print(snlp.keywords(5)) #關(guān)鍵詞抽取
print(snlp.summary(3)) #關(guān)鍵句抽取
>>>
['中國(guó)', '高考', '年', '疫情', '一月']
['因新冠疫情延期一月的中國(guó)高考拉開帷幕', '北京新一輪疫情得到控制', '最近幾年他發(fā)表多篇文章批評(píng)中國(guó)當(dāng)局']
['香港', '反對(duì)', '移民', '干涉', '本周']
['本周BBC中文采訪探討這一政策是否會(huì)導(dǎo)致香港移民潮', '香港《國(guó)安法》在香港和海外持續(xù)發(fā)酵', '西方國(guó)家對(duì)香港《國(guó)安法》反應(yīng)強(qiáng)烈']
['中國(guó)', '連續(xù)', '月', '疫情', '年']
['中國(guó)股市滬深300指數(shù)已連續(xù)七個(gè)交易日上漲', '中國(guó)股市在7月初則迎來一輪暴漲', '促使本輪股市上漲']
...
參考
The PageRank Citation Ranking: Bringing Order to the Web
TextRank: Bringing Order into Texts
