
爬蟲實(shí)戰(zhàn),文末有代碼鏈接,Python爬取安居客網(wǎng)站數(shù)據(jù)
背景
最近跟一個(gè)朋友聊天的過程中,朋友提到最近工作上被老板安排了一個(gè)任務(wù),要她對(duì)某個(gè)城市的二手房數(shù)據(jù)進(jìn)做一下分析,并做一個(gè)數(shù)據(jù)分析報(bào)告。而這些房源的數(shù)據(jù)基本都在幾大房產(chǎn)交易網(wǎng)站上,如果靠她個(gè)人一頁一頁的瀏覽下載太慢了,在如今工作如此內(nèi)卷的情況下,等她下載完數(shù)據(jù)分析完,老板估計(jì)得立馬讓她卷鋪蓋走人了。
但如果用程序自動(dòng)訪問這些頁面,解析頁面數(shù)據(jù),然后獲取需要的數(shù)據(jù)到本地,再進(jìn)行分析,就能快很多了。而這個(gè)過程用Python來完成正合適不過,于是我告訴她這個(gè)簡單,我來幫她搞定,朋友聽完安心地點(diǎn)了一杯咖啡繼續(xù)內(nèi)卷去了,于是,我開始負(fù)責(zé)搞定這個(gè)Python爬蟲腳本。
Python爬蟲開發(fā)步驟
其實(shí),無論是用Python還是用其他編程語言來開發(fā)一個(gè)爬蟲爬取某個(gè)網(wǎng)站的數(shù)據(jù),一般都會(huì)分為如下幾個(gè)步驟:
待爬取頁面的訪問url探索和獲取; 待爬取頁面的頁面元素的探查和分析; 訪問url獲取網(wǎng)頁數(shù)據(jù); 解析網(wǎng)頁數(shù)據(jù)獲取自己想要的結(jié)果; 將結(jié)果數(shù)據(jù)保存到本地文件;
所以,接下來,我就分如上5個(gè)步驟分別講解一下這個(gè)Pytho爬蟲腳本如何開發(fā)。
1. 待爬取頁面的訪問url探索和獲取
步驟一是對(duì)待爬取頁面訪問url的探索和獲取
有人說,獲取要爬取頁面的訪問url還不簡單,網(wǎng)站上點(diǎn)一下鏈接看一下瀏覽器地址欄的鏈接地址不就行了。大家可以去試試,有的網(wǎng)站可能確實(shí)如此簡單,但有的網(wǎng)站靠這樣的方式是獲取不到的。
比如,我們先拿一個(gè)簡單的網(wǎng)站來說,比如有這樣一個(gè)博客網(wǎng)站《螞蟻學(xué)Phthon》,假如我想爬取這個(gè)網(wǎng)站上的博客文章列表,如下圖紅框所示:

大家可以點(diǎn)一下紅框的文章以及點(diǎn)一下翻頁,然后看一下瀏覽器地址欄的鏈接地址,可以看到,每點(diǎn)一個(gè)文章或者翻頁,瀏覽器地址欄的鏈接地址都會(huì)變化,反映的是當(dāng)前你訪問的url地址,具體是長如下這樣的:
#每篇文章url的正則
pattern = r'^http://www.crazyant.net/\d+.html$'
#文章列表url的正則
pattern = r'^http://www.crazyant.net/page/\d+$'
所以,這個(gè)網(wǎng)站假如我們要爬取所有的文章列表數(shù)據(jù),那就很簡單了,因?yàn)閺臑g覽器地址欄我們就可以很方便地獲取到要爬取的每個(gè)文章列表頁的url地址,然后根據(jù)特征用正則進(jìn)行匹配。
但不是所有網(wǎng)站都是如此簡單的,我們?cè)賮砜匆幌铝硗庖粋€(gè)博客網(wǎng)站博客園,大家可以自己訪問看一下。假如我同樣希望爬取這個(gè)博客網(wǎng)站所有的文章列表數(shù)據(jù),那如何獲取到每個(gè)文章列表頁面的url呢?
如果大家實(shí)際點(diǎn)過翻頁就會(huì)發(fā)現(xiàn),點(diǎn)完后瀏覽器地址欄的地址是這樣的:

也即瀏覽器地址是長這樣子的:
#文章列表頁的正則
pattern = r'^https://www.cnblogs.com/#p\d+$
我們會(huì)看到地址里面有一個(gè)#號(hào),如果我們直接訪問這個(gè)url,能獲取到我們想要的文章列表數(shù)據(jù)嗎?大家可以用下面的代碼自己試一下:
import requests
r = requests.get('https://www.cnblogs.com/#p5',timeout=3)
if r.status_code == 200:
resp = r.text
print(resp)
可以看到,直接訪問瀏覽器地址的url是拿不到我們希望的文章列表頁的返回?cái)?shù)據(jù)的。因?yàn)檫@個(gè)網(wǎng)站是一個(gè)所謂的SPA應(yīng)用(Single Page Application),地址欄的#號(hào)是一個(gè)Hash,改變Hash 不會(huì)重新加載頁面。SPA應(yīng)用的典型特征是,首次訪問會(huì)加載整個(gè)頁面框架,然后通過Ajax/Fetch異步獲取數(shù)據(jù)更新頁面內(nèi)容。
所以,在這種情況下,我們只能借助于抓包工具比如chrome的開發(fā)者工具,來探索和獲取真實(shí)的Ajax/Fetch的url,如下圖所示:
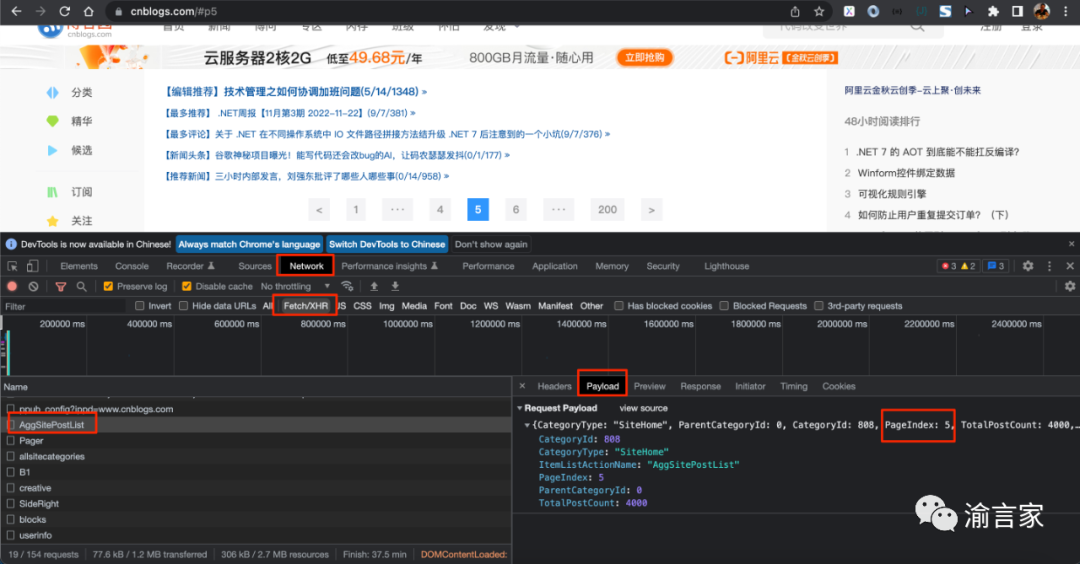
Chrome的開發(fā)者工具中的Network面板,可以很方便的獲取到當(dāng)前訪問頁面的各類請(qǐng)求資源,比如靜態(tài)的Html/js/css/圖片、動(dòng)態(tài)的Fetch/XHR異步請(qǐng)求等,我們打開Network面板下的子面板Fetch/XHR,就可以看到所有的異步請(qǐng)求。點(diǎn)擊某一個(gè)異步請(qǐng)求,我們就可以查看這個(gè)請(qǐng)求的request header、response header、cookies、請(qǐng)求提交的數(shù)據(jù)等信息。
我們通過探查,可以發(fā)現(xiàn),有一個(gè)POST的異步請(qǐng)求:
https://www.cnblogs.com/AggSite/AggSitePostList
在他的Playload也即post提交的數(shù)據(jù)里,有一個(gè)"PageIndex:5"的字段,正好對(duì)應(yīng)當(dāng)前的頁碼,通過進(jìn)一步探查response面板的內(nèi)容,我們就可以進(jìn)一步確認(rèn),這個(gè)異步請(qǐng)求才是我們真正要爬取的url。
所以,大家看到了,對(duì)于爬蟲開發(fā)的第一步,并不都是如大家想象的那么簡單,對(duì)于有的網(wǎng)站,還是需要利用類似Chrome開發(fā)者工具這樣的抓包工具做一些探查工作的。
好了,利用上述的思路,我也對(duì)我們這次真正要爬取的某房產(chǎn)網(wǎng)站頁面進(jìn)行了一次探查,獲取到了我要爬取的url,這次要爬取的網(wǎng)站的url獲取還是比較簡單的,屬于第一種情況,在這里就不詳述過程了。
2. 待爬取頁面的頁面元素的探查和分析
步驟二是對(duì)待爬取頁面的頁面元素進(jìn)行探查和分析
對(duì)頁面元素進(jìn)行探查分析的工作,還是會(huì)用到我們之前提到的Chrome開發(fā)者工具,而要探查什么內(nèi)容,則取決于我們要爬取的數(shù)據(jù)是什么。比如這次我們的需求是要爬取某房產(chǎn)網(wǎng)站的二手房房源新消息,那我們的探查就會(huì)類似下圖所示:
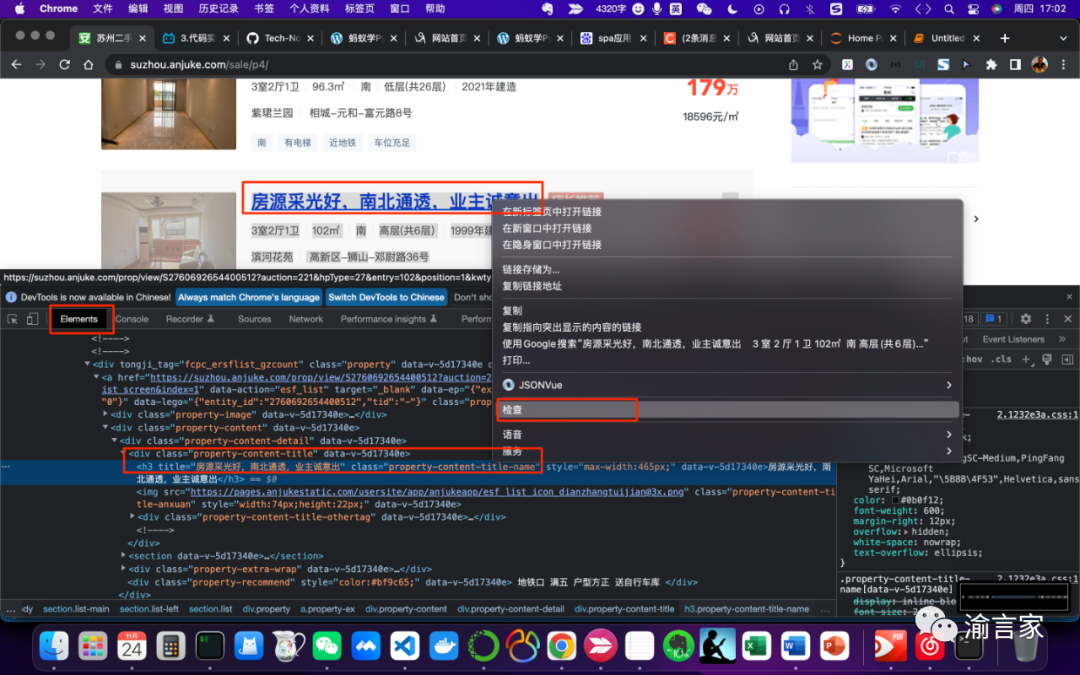
從圖中可以看到,假如我們想獲取房源的信息,那我們可以在房源標(biāo)題上右鍵,然后選擇檢查,這時(shí)就會(huì)打開Chrome開發(fā)者工具的Elements面板,直接定位到對(duì)應(yīng)的元素節(jié)點(diǎn),從圖中我們可以看到對(duì)應(yīng)的節(jié)點(diǎn)是一個(gè)h3標(biāo)簽節(jié)點(diǎn),同時(shí)我們也相應(yīng)能夠很清晰地看到節(jié)點(diǎn)的屬性有哪些,哪些屬性能夠準(zhǔn)確唯一地定位這個(gè)節(jié)點(diǎn)。比如這個(gè)h3節(jié)點(diǎn)有一個(gè)class屬性值為“property-content-title-name”,這個(gè)屬性可能不能唯一定位一個(gè)節(jié)點(diǎn),但如果我們通過定位他的父節(jié)點(diǎn),然后通過父節(jié)點(diǎn)尋找其下所有"class='property-content-title-name'"的子節(jié)點(diǎn),則能夠幫我們準(zhǔn)確的定位。
好了,用如上同樣的方法,我們可以逐步對(duì)我們要獲取的數(shù)據(jù)對(duì)應(yīng)的網(wǎng)頁元素進(jìn)行一一探查,這些探查的結(jié)果,將幫助我們后續(xù)開發(fā)頁面解析的腳本代碼。
3. 訪問url獲取網(wǎng)頁數(shù)據(jù)
步驟三是訪問待爬取的url獲取網(wǎng)頁數(shù)據(jù)
使用Python提供的requests庫,我們可以方便的訪問url獲取數(shù)據(jù)
如果我們只是簡單的手工獲取一頁的數(shù)據(jù),那是很簡單的,但如果我們用腳本自動(dòng)地高頻地訪問url獲取數(shù)據(jù),則需要考慮如何繞過網(wǎng)站的反爬的機(jī)制了。簡單的說,如果某個(gè)ip地址在某段時(shí)間內(nèi)高頻地訪問網(wǎng)站,則可能觸發(fā)網(wǎng)站的反爬機(jī)制,ip可能會(huì)被封禁。
另外,還要考慮一個(gè)問題是,網(wǎng)站一般會(huì)對(duì)來訪者進(jìn)行一些安全的校驗(yàn),來識(shí)別來訪者是真實(shí)的用戶還是類似我們爬蟲這樣的robot,所以,我們需要把我們的爬蟲腳本偽裝成一個(gè)真實(shí)的用戶來訪問。
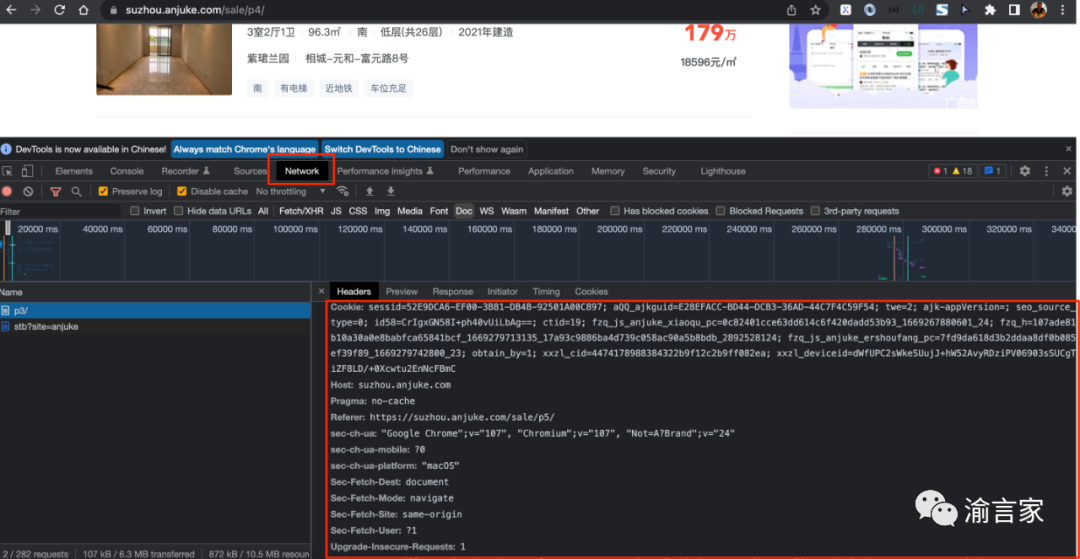
用戶偽裝的方法,就是獲取到我們要爬取的url請(qǐng)求的request headers數(shù)據(jù),然后在發(fā)送我們的request的時(shí)候,把該請(qǐng)求頭帶上,最重要的是cookies、User-Agent等字段,如下圖所示:
具體在python腳本中的代碼則是如下所示:
import requests
#構(gòu)造url的request headers,偽裝成正常用戶
headers = {
'accept':'',
'accept-encoding': '',
'accept-language': '',
'cookie': '',
......
'user-agent': ''
}
r = requests.get(url=craw_url,headers=headers,timeout=3)
上面的代碼我略去了部分header字段以及具體的header字段值,大家從Chrome開發(fā)者工具拷貝出來然后填進(jìn)去就行。
而關(guān)于如何避免同一個(gè)IP高頻的訪問同一個(gè)網(wǎng)站,我采取的是使用代理IP服務(wù)的方式。原理簡單的說,就是我通過一個(gè)代理IP的API服務(wù),批量獲取一個(gè)IP Pool,然后同一時(shí)間多個(gè)不同的線程拿不同的代理IP去訪問不同的頁面,這樣就避免了同一個(gè)時(shí)間同一IP高頻訪問的問題。
這樣的代理IP服務(wù)商市面上應(yīng)該有很多,大家自己找一下就好,為避免打廣告嫌疑,我就不直接說我用的是哪家了,直接上使用代理IP API服務(wù)的代碼大家自行觀摩吧:
def get_proxies():
proxy_list = []
#這里是我使用的代理IP服務(wù)商的API接口,敏感的參數(shù)值信息我用xxx代替了
proxy_url = 'http://api.tianqiip.com/getip?secret=xxx&num=1&type=json&port=1&time=3&mr=1&sign=xxx'
try:
datas = requests.get(proxy_url).json()
#如果代理ip獲取成功
if datas['code'] == 1000:
data_array = datas['data']
for i in range(len(data_array)):
proxy_ip = data_array[i]['ip']
proxy_port = str(data_array[i]['port'])
proxy = proxy_ip + ":" + proxy_port
proxy_list.append({'http':'http://'+proxy,'https':'http://'+proxy})
else:
code = datas['code']
print(f'獲取代理失敗,狀態(tài)碼={code}')
return proxy_list
except Exception as e:
print('調(diào)用天啟API獲取代理IP異常:'+ e)
return proxy_list
#在使用代理的情況下,需要在請(qǐng)求url數(shù)據(jù)的時(shí)候傳入proxies參數(shù)值為我們獲取的proxy
r = requests.get(url=craw_url,headers=headers,proxies=proxy,timeout=10)
好了,通過真實(shí)用戶偽裝和使用代理IP服務(wù),我們就可以用我們的腳本來自動(dòng)批量的訪問url獲取我們要爬取的url數(shù)據(jù)了。
通過代理IP服務(wù)商的API拿到IP Pool之后,我們可以啟動(dòng)多個(gè)線程進(jìn)行數(shù)據(jù)的爬取,代碼如下:
while crawlerUrlManager.has_new_url():
crawler_threads = []
for i in range(len(proxy_list)):
proxy = proxy_list[i]
crawler_thread = threading.Thread(target=craw_anjuke_suzhou,args=(crawlerUrlManager.get_url(),proxy))
crawler_threads.append(crawler_thread)
#啟動(dòng)線程開始爬取
for crawler_thread in crawler_threads:
crawler_thread.start()
for crawler_thread in crawler_threads:
crawler_thread.join()
#謹(jǐn)慎起見,一批線程爬取結(jié)束后,間隔一段時(shí)間,再啟動(dòng)下一批爬取,這里默認(rèn)設(shè)置為3秒,可調(diào)整
time.sleep(3)
大家看這段代碼的時(shí)候,會(huì)看到一個(gè)叫crawlerUrlManager的類,這個(gè)類主要用來對(duì)要爬取的url進(jìn)行管理的,記錄哪些url已經(jīng)被爬取,哪些url還沒有被爬取,因?yàn)樵谂廊〉倪^程中可能會(huì)碰到各種問題,尤其是網(wǎng)絡(luò)訪問相關(guān)的問題,所以有這么一個(gè)manager,可以在出現(xiàn)問題的時(shí)候告訴我們哪些url爬取成功了,還剩余哪些url待爬取,方便后續(xù)跟進(jìn)處理,這部分的核心代碼如下:
#新增一個(gè)待爬取Url
def add_new_url(self,url):
if url is None or len(url) == 0:
return
if url in self.new_urls or url in self.old_urls:
return
self.new_urls.add(url)
return True
#獲取一個(gè)要爬取的url
def get_url(self):
if self.has_new_url():
url = self.new_urls.pop()
self.old_urls.add(url)
return url
else:
return None
#判斷是否有待爬取的url
def has_new_url(self):
return len(self.new_urls) > 0
......
完整代碼大家可以從這里獲取:https://github.com/xiaoyuge/kingfish-python/tree/master/crawler/anjuke,或者關(guān)注我公眾號(hào):渝言家
4. 解析網(wǎng)頁數(shù)據(jù)獲取自己想要的結(jié)果
步驟四是對(duì)請(qǐng)求到的url數(shù)據(jù),進(jìn)行解析
Python提供了一些對(duì)html/xml格式內(nèi)容進(jìn)行解析的庫,我使用的是bs4這個(gè)庫。這個(gè)步驟就依賴于我們之前提到的第2步對(duì)網(wǎng)頁元素的分析和探索了,我們需要根據(jù)我們對(duì)網(wǎng)頁元素分析的結(jié)果,來決定這部分的代碼我們?cè)趺磳憽A硗庑枰f明的是,因?yàn)榫W(wǎng)站可能會(huì)不定期進(jìn)行升級(jí),升級(jí)的過程中可能會(huì)改變網(wǎng)頁的元素結(jié)構(gòu),因此,如果網(wǎng)站發(fā)生了升級(jí),那我們?cè)葘懞玫木W(wǎng)頁解析的代碼很可能會(huì)不work了,可能需要根據(jù)升級(jí)后的網(wǎng)站元素結(jié)構(gòu)重新開發(fā)。
比如獲取剛才我們提到的房源標(biāo)題信息的代碼如下:
from bs4 import BeautifulSoup
#如果正常返回結(jié)果,開始解析
if r.status_code == 200:
content = r.text
soup = BeautifulSoup(content,'html.parser')
content_div_nodes = soup.find_all('div',class_='property-content')
for content_div_node in content_div_nodes:
#獲取房產(chǎn)標(biāo)題內(nèi)容
content_title_name = content_div_node.find('h3',class_='property-content-title-name')
title_name = content_title_name.get_text()
......
獲取其他數(shù)據(jù)的代碼就不一一列舉了,大同小異,關(guān)鍵就是根據(jù)第2步對(duì)網(wǎng)頁元素分析的結(jié)果來幫助代碼的編寫。
5. 將結(jié)果數(shù)據(jù)保存到本地文件
通過對(duì)頁面元素的解析,我們拿到了我們想要的數(shù)據(jù),為了便于后續(xù)的數(shù)據(jù)分析,我們需要把數(shù)據(jù)保存到本地,在這里我將結(jié)果保存到了一個(gè)csv文件,用”;“做分割符:
with open('crawler/anjuke/data/suzhouSecondHouse.csv','a') as fout:
fout.write("%s;%s;%s;%s;%s;%s;%s;%s;%s;%s;%s;%s;%s;%s;%s;%s;%s;%s\n"%(title_name,datas_shi,datas_ting,datas_wei,square_num,square_unit,orientations,floor_level,build_year,housing_estate,district,town,road,tagstr,total_price,total_price_unit,avarage_price_num,avarage_price_unit))
總結(jié)
如上我們就完整的介紹了爬取一個(gè)網(wǎng)站所需要的步驟,以及每個(gè)步驟下具體需要干什么事情以及如何寫Python代碼。完整的代碼可以從這個(gè)地址獲取:https://github.com/xiaoyuge/kingfish-python/tree/master/crawler/anjuke
但是,爬取網(wǎng)站拿到數(shù)據(jù)并不是目的,我們真正的目的是對(duì)數(shù)據(jù)進(jìn)行處理和分析,并進(jìn)行可視化的展現(xiàn)生成數(shù)據(jù)報(bào)告,才能應(yīng)付我朋友老板的差事。
看來,我們的任務(wù)還沒有完成,我朋友還不能安心的喝咖啡,下一篇我們來講一下如何對(duì)數(shù)據(jù)進(jìn)行分析并生成好看又好用的數(shù)據(jù)報(bào)告,感興趣的朋友可以關(guān)注我的公眾號(hào):渝言家。我是一個(gè)有著十多年經(jīng)驗(yàn)的資深技術(shù)開發(fā)和技術(shù)管理者,歷經(jīng)互聯(lián)網(wǎng)大廠和創(chuàng)業(yè)公司,在我的公眾號(hào)里,我會(huì)和大家一起聊聊對(duì)技術(shù)、管理、產(chǎn)品和行業(yè)的洞見。