
【關(guān)于 Word2vec】 那些你不知道的事
作者:楊夕
項目地址:https://github.com/km1994/NLP-Interview-Notes
個人論文讀書筆記:https://github.com/km1994/nlp_paper_study
【注:手機閱讀可能圖片打不開!!!】
一、Wordvec 介紹篇
1.1 Wordvec 指什么?
介紹:word2vec是一個把詞語轉(zhuǎn)化為對應(yīng)向量的形式。word2vec中建模并不是最終的目的,其目的是獲取建模的參數(shù),這個過程稱為fake task。
雙劍客
CBOW vs Skip-gram
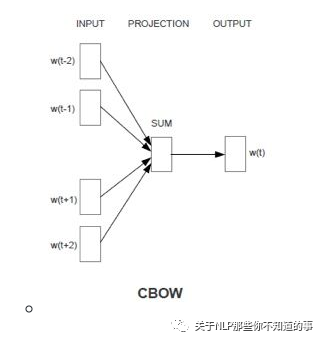
1.2 Wordvec 中 CBOW 指什么?
CBOW
思想:用周圍詞預(yù)測中心詞
輸入輸出介紹:輸入是某一個特征詞的上下文相關(guān)的詞對應(yīng)的詞向量,而輸出就是這特定的一個詞的詞向量
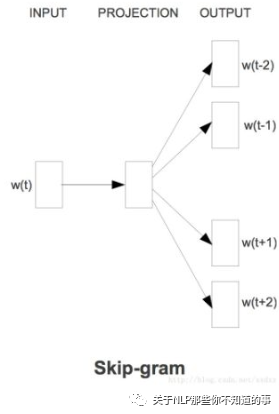
1.3 Wordvec 中 Skip-gram 指什么?
Skip-gram
思想:用中心詞預(yù)測周圍詞
輸入輸出介紹:輸入是特定的一個詞的詞向量,而輸出是特定詞對應(yīng)的上下文詞向量
1.4 CBOW vs Skip-gram 哪一個好?
CBOW 可以理解為 一個老師教多個學(xué)生;(高等教育)
Skip-gram 可以理解為 一個學(xué)生被多個老師教;(補習(xí)班)
那問題來了?
最后 哪個學(xué)生 成績 會更好?
二、Wordvec 優(yōu)化篇
2.1 Word2vec 中 霍夫曼樹 是什么?
HS用哈夫曼樹,把預(yù)測one-hot編碼改成預(yù)測一組01編碼,進行層次分類。
輸入輸出:
輸入:權(quán)值為(w1,w2,...wn)的n個節(jié)點
輸出:對應(yīng)的霍夫曼樹
步驟:
將(w1,w2,...wn)看做是有n棵樹的森林,每個樹僅有一個節(jié)點。
在森林中選擇根節(jié)點權(quán)值最小的兩棵樹進行合并,得到一個新的樹,這兩顆樹分布作為新樹的左右子樹。新樹的根節(jié)點權(quán)重為左右子樹的根節(jié)點權(quán)重之和。
將之前的根節(jié)點權(quán)值最小的兩棵樹從森林刪除,并把新樹加入森林。
重復(fù)步驟2)和3)直到森林里只有一棵樹為止。
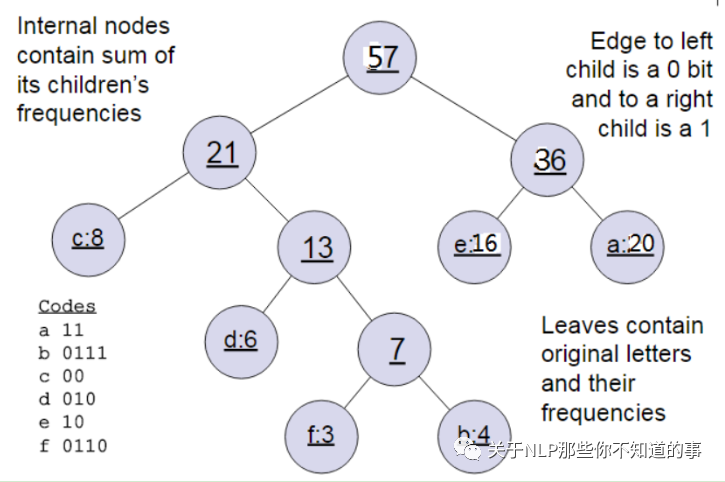
舉例說明: 下面我們用一個具體的例子來說明霍夫曼樹建立的過程,我們有(a,b,c,d,e,f)共6個節(jié)點,節(jié)點的權(quán)值分布是(20,4,8,6,16,3)。
首先是最小的b和f合并,得到的新樹根節(jié)點權(quán)重是7.此時森林里5棵樹,根節(jié)點權(quán)重分別是20,8,6,16,7。此時根節(jié)點權(quán)重最小的6,7合并,得到新子樹,依次類推,最終得到下面的霍夫曼樹。
2.2 Word2vec 中 為什么要使用 霍夫曼樹?
一般得到霍夫曼樹后我們會對葉子節(jié)點進行霍夫曼編碼,由于權(quán)重高的葉子節(jié)點越靠近根節(jié)點,而權(quán)重低的葉子節(jié)點會遠(yuǎn)離根節(jié)點,這樣我們的高權(quán)重節(jié)點編碼值較短,而低權(quán)重值編碼值較長。這保證的樹的帶權(quán)路徑最短,也符合我們的信息論,即我們希望越常用的詞擁有更短的編碼。如何編碼呢?一般對于一個霍夫曼樹的節(jié)點(根節(jié)點除外),可以約定左子樹編碼為0,右子樹編碼為1.如上圖,則可以得到c的編碼是00。
在word2vec中,約定編碼方式和上面的例子相反,即約定左子樹編碼為1,右子樹編碼為0,同時約定左子樹的權(quán)重不小于右子樹的權(quán)重。
2.3 Word2vec 中使用 霍夫曼樹 的好處?
由于是二叉樹,之前計算量為V,現(xiàn)在變成了log2V;
由于使用霍夫曼樹是高頻的詞靠近樹根,這樣高頻詞需要更少的時間會被找到,這符合我們的貪心優(yōu)化思想。
2.4 為什么 Word2vec 中會用到 負(fù)采樣?
動機:使用霍夫曼樹來代替?zhèn)鹘y(tǒng)的神經(jīng)網(wǎng)絡(luò),可以提高模型訓(xùn)練的效率。但是如果我們的訓(xùn)練樣本里的中心詞w是一個很生僻的詞,那么就得在霍夫曼樹中辛苦的向下走很久了;
介紹:一種概率采樣的方式,可以根據(jù)詞頻進行隨機抽樣,傾向于選擇詞頻較大的負(fù)樣本;
優(yōu)點:
用來提高訓(xùn)練速度并且改善所得到詞向量的質(zhì)量的一種方法;
不同于原本每個訓(xùn)練樣本更新所有的權(quán)重,負(fù)采樣每次讓一個訓(xùn)練樣本僅僅更新一小部分的權(quán)重,這樣就會降低梯度下降過程中的計算量。
2.5 Word2vec 中會用到 負(fù)采樣 是什么樣?
因為使用softmax時,分母需要將中心詞與語料庫總所有詞做點乘,代價太大:
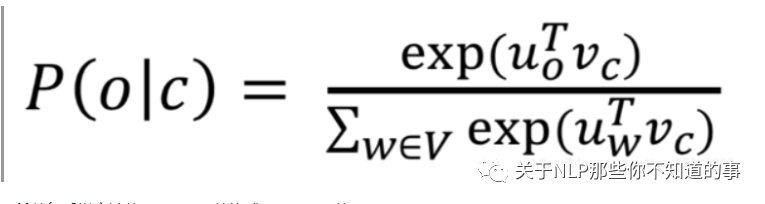
所以負(fù)采樣方法將softmax函數(shù)換成sigmoid函數(shù)。
選取K個負(fù)樣本,即窗口之外的樣本,計算中心詞與負(fù)樣本的點乘,最小化該結(jié)果。計算中心詞與窗口內(nèi)單詞的點乘,最大化該結(jié)果,目標(biāo)函數(shù)為:
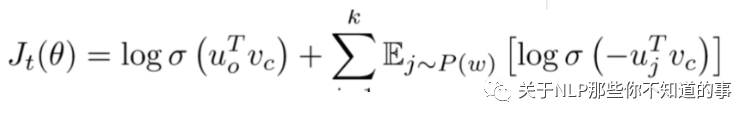
2.6 Word2vec 中 負(fù)采樣 的采樣方式?
NS是一種概率采樣的方式,可以根據(jù)詞頻進行隨機抽樣,我們傾向于選擇詞頻比較大的負(fù)樣本,比如“的”,這種詞語其實是對我們的目標(biāo)單詞沒有很大貢獻的。
Word2vec則在詞頻基礎(chǔ)上取了0.75次冪,減小詞頻之間差異過大所帶來的影響,使得詞頻比較小的負(fù)樣本也有機會被采到。
極大化正樣本出現(xiàn)的概率,同時極小化負(fù)樣本出現(xiàn)的概率,以sigmoid來代替softmax,相當(dāng)于進行二分類,判斷這個樣本到底是不是正樣本。
三、Wordvec 對比篇
3.1 word2vec和NNLM對比有什么區(qū)別?(word2vec vs NNLM)
NNLM:是神經(jīng)網(wǎng)絡(luò)語言模型,使用前 n - 1 個單詞預(yù)測第 n 個單詞;
word2vec :使用第 n - 1 個單詞預(yù)測第 n 個單詞的神經(jīng)網(wǎng)絡(luò)模型。但是 word2vec 更專注于它的中間產(chǎn)物詞向量,所以在計算上做了大量的優(yōu)化。優(yōu)化如下:
對輸入的詞向量直接按列求和,再按列求平均。這樣的話,輸入的多個詞向量就變成了一個詞向量。
采用分層的 softmax(hierarchical softmax),實質(zhì)上是一棵哈夫曼樹。
采用負(fù)采樣,從所有的單詞中采樣出指定數(shù)量的單詞,而不需要使用全部的單詞
3.2 word2vec和tf-idf 在相似度計算時的區(qū)別?
word2vec 是稠密的向量,而 tf-idf 則是稀疏的向量;
word2vec 的向量維度一般遠(yuǎn)比 tf-idf 的向量維度小得多,故而在計算時更快;
word2vec 的向量可以表達語義信息,但是 tf-idf 的向量不可以;
word2vec 可以通過計算余弦相似度來得出兩個向量的相似度,但是 tf-idf 不可以;
四、word2vec 實戰(zhàn)篇
4.1 word2vec訓(xùn)練trick,window設(shè)置多大?
window設(shè)置:
比較大,會提取更多的topic信息
設(shè)置比較小的話會更加關(guān)注于詞本身。
默認(rèn)參數(shù)是5,但是在有些任務(wù)中window為2效果最好,比如某些英語語料的短文本任務(wù)(并非越大越好)
4.1 word2vec訓(xùn)練trick,詞向量緯度,大與小有什么影響,還有其他參數(shù)?
詞向量維度代表了詞語的特征,特征越多能夠更準(zhǔn)確的將詞與詞區(qū)分,就好像一個人特征越多越容易與他人區(qū)分開來。但是在實際應(yīng)用中維度太多訓(xùn)練出來的模型會越大,雖然維度越多能夠更好區(qū)分,但是詞與詞之間的關(guān)系也就會被淡化,這與我們訓(xùn)練詞向量的目的是相反的,我們訓(xùn)練詞向量是希望能夠通過統(tǒng)計來找出詞與詞之間的聯(lián)系,維度太高了會淡化詞之間的關(guān)系,但是維度太低了又不能將詞區(qū)分,所以詞向量的維度選擇依賴于你的實際應(yīng)用場景,這樣才能繼續(xù)后面的工作。一般說來200-400維是比較常見的。
參考資料
word2vec原理(一) CBOW與Skip-Gram模型基礎(chǔ)
word2vec原理(二) 基于Hierarchical Softmax的模型
word2vec原理(三) 基于Negative Sampling的模型
神經(jīng)網(wǎng)路語言模型(NNLM)的理解
NLP 面試題(一)和答案,附有參考URL
